[Reading] You Only Look Once: Unified, Real-Time Object Detection
You Only Look Once: Unified, Real-Time Object Detection (2015/6)
Contents
1. 概述
文章的主要贡献有:
- 将目标检测问题看成是对边界框和类别概率的回归问题,提出了可以同时对边界框和类别概率进行预测的网络架构,称为 YOLO(You Only Look Once)。由于整个流水线只有单个网络,可以端到端地进行优化,且预测速度很快,可以实现实时检测。此外 YOLO 还可以学到目标的泛化表示,具有很强的泛化能力。
- 通过对 YOLO 和 Fast R-CNN 的错误分析,指出二者会犯不同的错误:YOLO 具有更少的背景错误(background error)和更多的定位错误(localization error),将二者结合可以得到更好的效果。
在 R-CNN 系列的目标检测方法中,需要先对输入图片生成一系列候选框,在候选框上进行类别预测,并对候选框进行微调。整个流水线分为多个步骤,非常耗时且难以优化。文章将目标检测问题看成是单个回归问题,直接从图像像素预测边界框和类别概率,如 Figure 1 所示。

YOLO 通过单个卷积网络同时预测多个边界框和类别概率,由此带来一系列好处:
- YOLO 的速度非常快:由于只有一个网络,整个检测流水线非常简单,只需一次前向传播即可。
- YOLO 在预测时可以充分利用图像的全局信息:YOLO 在训练和测试时可以看到整张图像,可以隐式地对类别的上下文进行编码;相比之下,基于滑窗和候选区域的方法视野有限,无法看到完整的图像。因此 YOLO 的背景错误比 Fast R-CNN 少一半。
- YOLO 可以学到目标的泛化表示:在自然图像上训练的 YOLO,也可以在艺术图像上获得很好的效果。
相比当时最佳的检测系统,YOLO 的准确率略低。由于网格划分较稀疏,且在每个网络单元内只预测少量边界框(文中为 2 个),YOLO 难以对目标(尤其是小目标)进行精确的定位。
2. 统一的检测
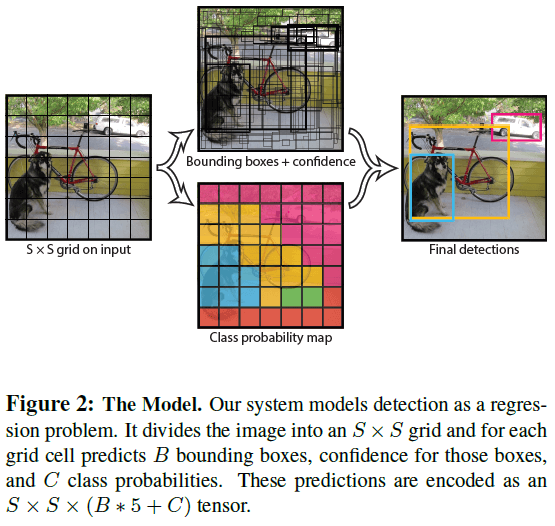
YOLO 将输入图像划分为 $S \times S$ 的网格,如果物体的中心落入某个格子,则该格子负责检测这个物体,如 Figure 2 所示。
每个格子会预测 $B$ 个边界框,以及每个边界框的置信度,置信度表示了模型认为边界框内有物体的信心以及边界框的准确程度,定义为 $\mathrm{Pr}(\mathrm{Object}) * \mathrm{IOU}_{\mathrm{prod}}^{\mathrm{truth}}$。如果格子内没有物体,则置信度应为 0;否则我们希望置信度应为预测框和标注框的 IOU。
每个边界框包含 5 个预测值:$x, y, w, h$ 和置信度。$(x, y)$ 为边界框中心的坐标,$w$ 和 $h$ 为边界框相对于整张图像的宽高。
对于有 $C$ 个类别的检测任务,网格中的每个格子会预测 $C$ 个条件概率 $\mathrm{Pr}(\mathrm{Class}_i|\mathrm{Object})$,即在格子内有物体的条件下,该物体的类别为 $\mathrm{Class}_i$ 的概率。注意这组预测与边界框的数量无关。测试时使用
$$
\mathrm{Pr}(\mathrm{Class}_i|\mathrm{Object}) * \mathrm{Pr}(\mathrm{Object}) * \mathrm{IOU}_{\mathrm{prod}}^{\mathrm{truth}} = \mathrm{Pr}(\mathrm{Class}_i) * \mathrm{IOU}_{\mathrm{prod}}^{\mathrm{truth}} \tag{1}
$$
得到每个边界框对应的类别相关的置信度,同时反映了边界框内有对应类别物体的概率,以及边界框和物体的拟合程度。
网络的最终输出尺寸为 $S \times S \times (B * 5 + C)$ 的张量。在 PASCAL VOC 数据上(20 个类别),文章使用 $S = 7$,$B = 2$,$C = 20$,最终的预测输出为 $7 \times 7 \times 30$ 的张量。
2.1. 网络设计
YOLO 包含 24 个卷积层和 2 个全连接层,卷积层用于提取特征,全连接层用于输出概率和坐标。受 GoogLeNet 启发,文章简化了 inception 模块,只使用了 $1 \times 1$ 压缩后接 $3 \times 3$ 卷积的形式,如 Figure 3 所示。

文章还给出了 YOLO 的快速版本,将 24 层卷积减少为 9 层,同时也减少了过滤器数量,称为 Fast YOLO。
2.2. 训练
文章先在前 20 个卷积层后面加上了一层平均池化和一层全连接层,使用 ImageNet 数据集对卷积网络进行预训练。然后在前 20 个卷积层后,添加 4 个卷积层和 2 个全连接层,来进行检测任务。由于检测通常需要更细粒度的视觉信息,文章同时将输入分辨率从 $224 \times 224$ 提高到 $448 \times 448$。
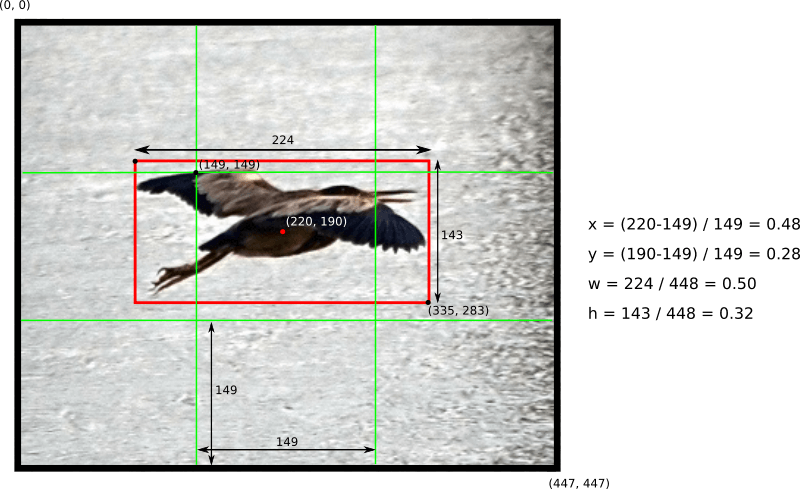
网络最后一层输出类别概率和边界框坐标。边界框的宽 $w$ 和高 $h$ 按图像宽高进行了归一化,取值范围在 0 到 1 之间。边界框中心的坐标 $(x, y)$ 是所在网格内的偏移量,使用格子尺寸归一化,取值范围也在 0 到 1 之间。Understanding YOLO 中给出了一个计算边界框坐标的形象例子,如下图。
YOLO 在最后一层使用了线性激活函数,在其它层则使用了 Leaky ReLU,即
$$
\phi(x) =
\begin{cases}
x, & \text{if } x > 0 \\
0.1x, & \text{otherwise}
\end{cases}
$$
从便于优化的角度考虑,文章选择了误差平方和作为优化目标。这样会带来两个问题:
- 误差平方和会同等地对待定位误差和分类误差,而实际数据中大部分网格中都没有目标,这些格子的置信度会趋于零,平均下来会掩盖有目标的格子的梯度。为此文章进入了两个系数 $\lambda_{\mathrm{coord}}$ 和 $\lambda_{\mathrm{noobj}}$ 对边界框预测损失和无目标时的置信度预测损失进行平衡,增加前者并降低后者。文章设置 $\lambda_{\mathrm{coord}} = 5$,$\lambda_{\mathrm{noobj}} = 0.5$。
- 误差平方和会同等地对待大边界框和小边界框,但实际上对于同等的定位误差,其对小边界框的影响要大于大边界框。为此文章使用了边界框宽高的平方根。
YOLO 会在一个格子内预测多个边界框,相当于有多个边界框预测器。训练时,对每个物体,选择与标注框 IOU 最大的边界框,使得每个物体只有一个预测器负责预测。这样可以让不同的边界框预测器专精于不同尺寸、长宽比例、类别的对象,提高整体的召回。
训练时使用了多目标的损失函数
$$
\begin{aligned}
& \lambda_{\mathrm{coord}} \sum_{i=1}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\mathrm{obj}} \Big[(x_i – \hat{x}_i)^2 + (y_i – \hat{y}_i)^2 \Big] \\
& + \lambda_{\mathrm{coord}} \sum_{i=1}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\mathrm{obj}} \Big[\Big(\sqrt{w_i} – \sqrt{\hat{w}_i}\Big)^2 + \Big(\sqrt{h_i} – \sqrt{\hat{h}_i}\Big)^2 \Big] \\
& + \sum_{i=1}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\mathrm{obj}} (C_i – \hat{C}_i)^2 \\
&+ \lambda_{\mathrm{noobj}} \sum_{i=1}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\mathrm{noobj}} (C_i – \hat{C}_i)^2 \\
&+ \sum_{i=1}^{S^2} \mathbb{1}_{i}^{\mathrm{obj}} \sum_{c \in \mathrm{classes}} \big(p_i(c) – \hat{p}_i(c)\big)^2
\end{aligned} \tag{3}
$$
其中:
- 第 1 行为边界框中心坐标的损失,$\mathbb{1}_{ij}^{\mathrm{obj}}$ 表示第 $i$ 个格子的第 $j$ 个边界框预测器负责预测边界框,即仅对负责该物体的 1 个预测器所生成边界框的误差进行惩罚,其余 $B – 1$ 个边界框的误差不计算在内;
- 第 2 行为边界框长宽的损失,如前所述,使用了长宽的平方根;
- 第 3 行为置信度的损失;
- 第 4 行为无物体时置信度的损失,权重为 $\lambda_{\mathrm{noobj}}$;
- 第 5 行为分类损失,$\mathbb{1}_{i}^{\mathrm{obj}}$ 表示物体出现在第 $i$ 个格子,仅当格子中存在物体时,损失函数才对分类误差进行惩罚。
2.3. 推断
YOLO 只需一次前向传播即可完成预测,在 PASCAL VOC 上,单张图像一次预测输出 98 个边界框,以及每个边界框的类别概率。通常物体都会明确地落入一个网格单元,网络只预测一个边界框。对于一些大物体,或者位于网格边缘的物体,可能会被多个网格单元定位,可以通过 NMS 进行过滤。使用 NMS 可以提升 2% 到 3% 的 mAP。
2.4. 局限性
文章还分析了 YOLO 的局限性,包括:
- YOLO 在每个网格单元只预测两个边界框,是一个非常强的限制,难以检测成群出现的小物体。
- YOLO 直接学习预测边界框,难以泛化到没见过的或少见的位置和比例。
- YOLO 的训练损失只是检测性能的近似,如前所述,小误差对小框 IOU 的影响要大于对大框的影响,而误差平方和会同等对待这两种情况。错误定位是 YOLO 的主要误差来源。
3. 实验结果
3.1. 性能
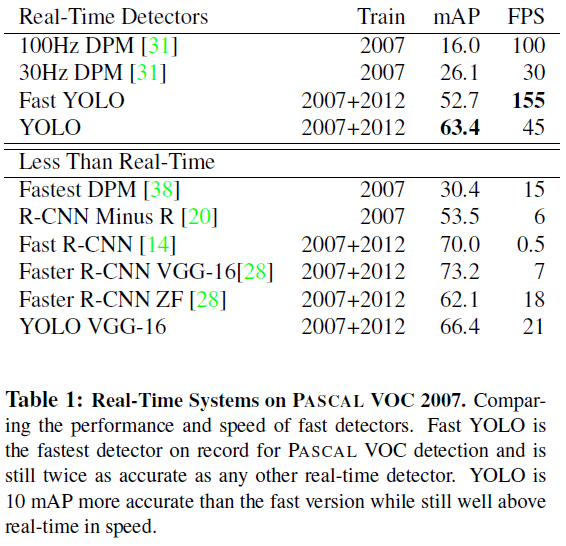
文章在 PASCAL VOC 2007 上比较了 YOLO 和其他实施检测系统的性能如 Table 1 所示。可见在实时检测器中,YOLO 获得了最高的 63.4 mAP。在 YOLO 中使用 VGG 后 mAP 可以提高到 66.4。
3.2. 错误分析
文章统计了 YOLO 预测的以下 5 种情况:
- Correct:类别正确,$IOU > 0.5$
- Localization:类别正确,$0.1 < IOU < 0.5$
- Similar:类别相似,$IOU > 0.1$
- Other:类别错误,$IOU > 0.1$
- Background:所有对象的 $IOU < 0.1$
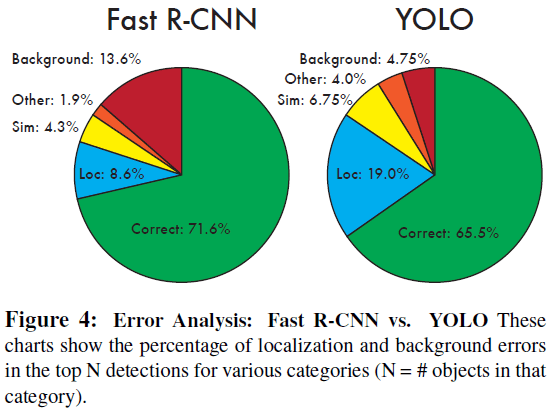
结果如 Figure 4 所示,可见与 Fast R-CNN 相比,YOLO 犯了更多的定位错误。YOLO 的定位错误数量相当于其他错误之和。Fast R-CNN 的定位错误更少,但有更多的背景错误,13.6% 的检测结果是假阳性。
3.3. 结合 Fast R-CNN 和 YOLO
由错误分析可见,Fast R-CNN 和 YOLO 各有特点,文章将二者结合起来,同时使用二者对图像进行检测,对 R-CNN 预测的每个边界框,检查 YOLO 是否预测了类似的边界框,如果是,则根据 YOLO 预测的概率和两个框的 IOU 提升 R-CNN 预测的对应边界框。结果如 Table 2 所示,可见结合后的模型 mAP 提升了 3.2%,达到了 75.0%。
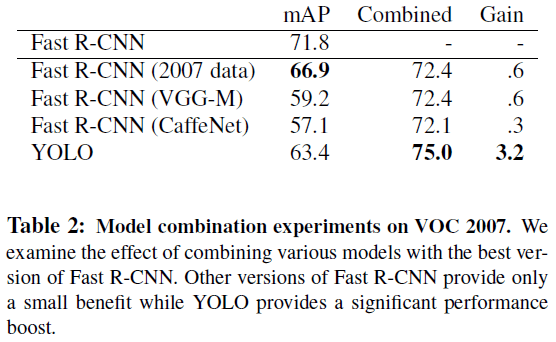
文章指出,结合 Fast R-CNN 和 YOLO 获得的提升不仅来自模型融合,还是因为二者会犯不同类型的错误。由 Table 2 可见,融合不同类型的 Fast R-CNN 并没有带来显著提升。
3.4. VOC 2012 结果
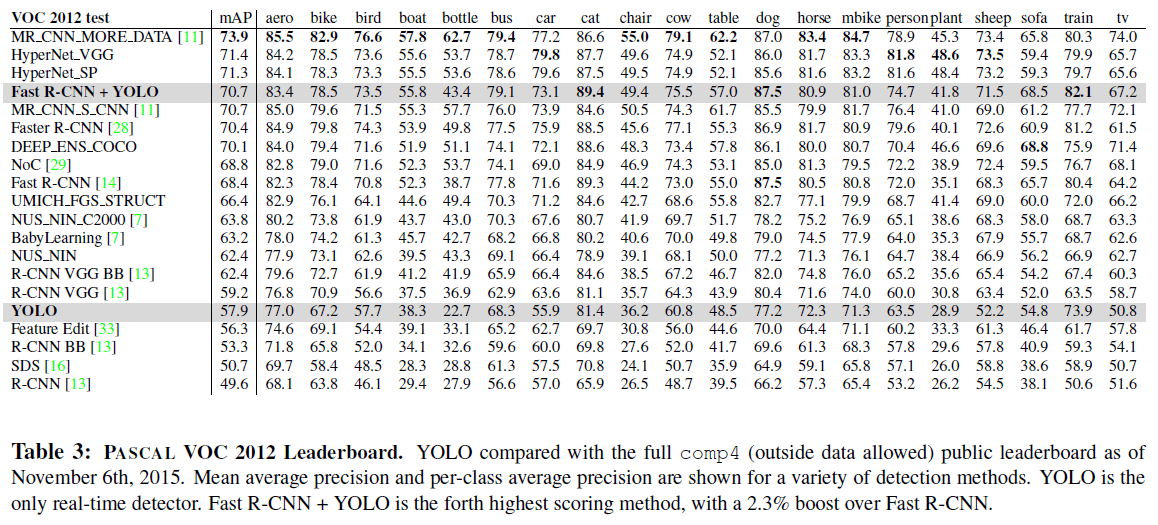
文章给出了 YOLO 在 VOC 2012 上的结果如 Table 3 所示。
3.5. 泛化能力
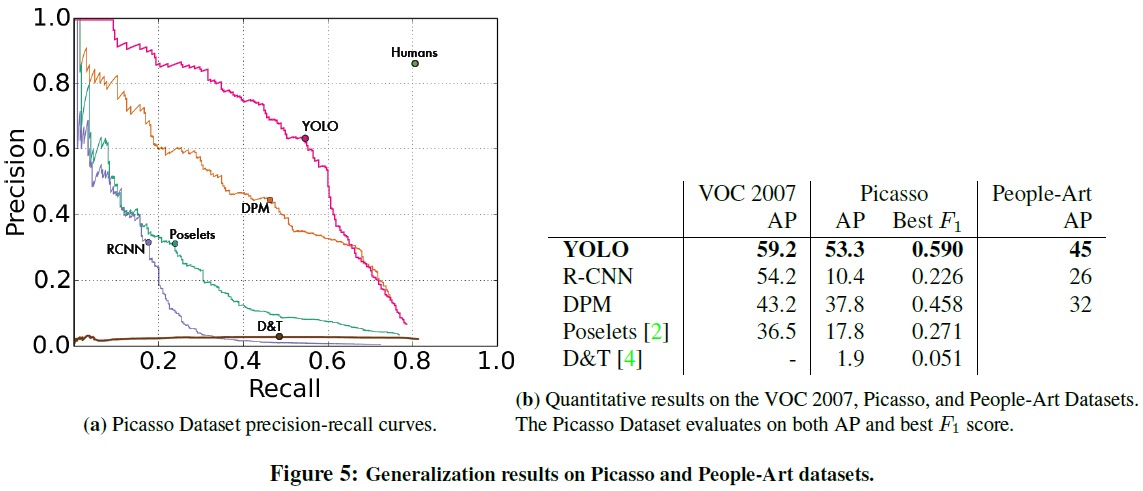
文章比较了 YOLO 和其他检测方法在艺术图像上的性能,如 Figure 5 所示。这些检测模型都是在自然图像数据集 VOC 2007 上训练的。艺术图像和自然图像在像素级别上有较大差异,而在更宏观的尺寸和形状上相似。YOLO 能对物体的尺寸、形状,以及物体间的关系建模,用于艺术图像时,YOLO 仍能保持较高的 mAP。