[Reading] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2015/6)
Contents
1. 概述
文章的主要贡献有:
- 提出了 Region Proposal Network(RPN),通过共享检测网络的卷积特征,可以几乎零成本地生成候选区域。RPN 是一种全卷积网络,可以同时预测对象的边界框并给出对象分数(objectness score),可以端到端地进行训练。
- 引入了锚点框(anchor box)的概念,以不同尺寸和比例的锚点框为参考来预测边界框,使得 RPN 能够预测不同尺寸和比例的边界框。
- 将 RPN 和 Fast R-CNN 整合到一个网络中,共享卷积特征,并引入注意力机制,构造了称为 Faster R-CNN 检测网络,在提高检测速度的同时还提高了准确率。
- 给出了一种同时训练 RPN 和识别网络的方法,加快训练速度。
对于如 R-CNN、Fast R-CNN 这些基于候选区域的的目标检测网络,把生成候选区域和识别看成两个独立的任务,其中生成候选区域这一步骤耗费了大量时间。这两个任务都是在同一张图像上的计算,应该有能够共享的部分。文章指出,对于这些基于候选区域的检测器,可以通过特征图来生成候选区域:RPN 通过在特征图上添加一系列卷积层,在各个位置上进行边界框回归和 objectness score 预测。
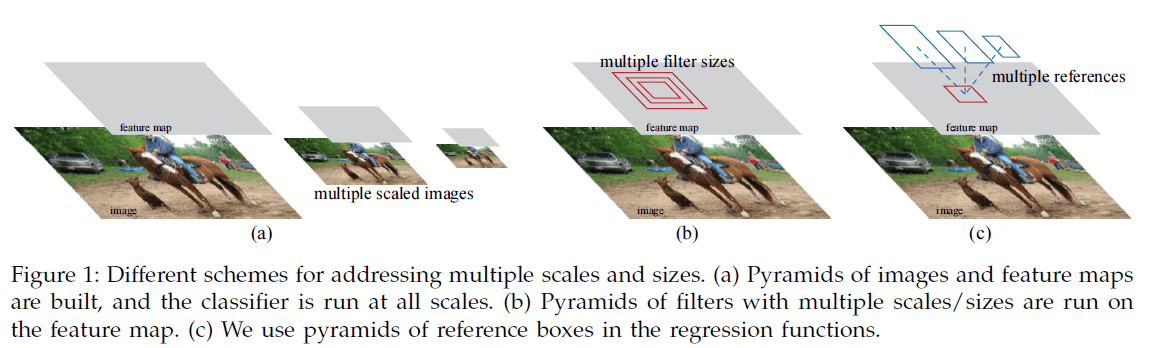
为了生成不同尺寸和长宽比例的候选框,RPN 引入了锚点框(anchor box),即预先定义多个不同尺寸和比例的框作为参考(Figure 1c),在此基础上预测候选框,避免使用图像金字塔(Figure 1a)或者过滤器金字塔(Figure 1b)。
为了同时训练 RPN 和识别网络,文章给出了一种交替对二者进行微调的训练方法,先对 RPN 进行微调,再固定候选区域,对识别网络进行微调,交替进行。这个方法可以快速收敛,最终得到能够在生成候选区域和目标识别两个任务上共享卷积特征的统一网络。
2. Faster R-CNN
Faster R-CNN 包含两个模块,分别是用于生成候选区域的深度全卷积网络即 RPN,以及用于识别候选区域的 Fast R-CNN 检测器,如 Figure 2 所示。

2.1. RPN
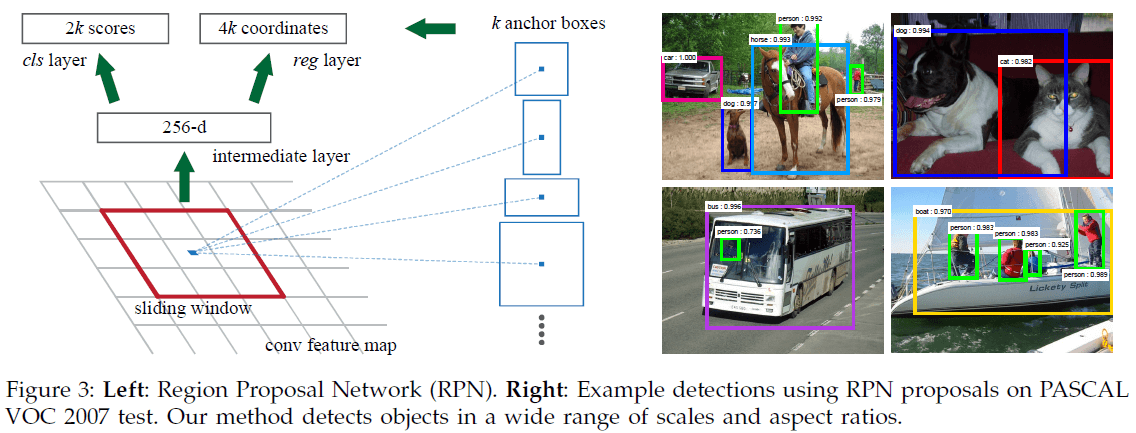
RPN 的输入为一张任意尺寸的图像,输出为一组矩形候选区域,每一个区域有一个 objectness score。RPN 与 Fast R-CNN 检测器共享一系列卷积层,在最后一个共享卷积层的特征图上,使用一个输入为 $n \times n$ 的小网络进行滑动(文章选择 $n = 3$),将窗口内的特征图映射为低维特征,分别提供给边界框回归层(reg)和边界框分类层(cls)这两个全连接层,如 Figure 3 左图所示,注意这里的“分类”只是对该处是否有物体进行分类,不对物体类别进行分类。两个全连接层的参数是在所有位置共享的,整个结构可以实现为一个 $n \times n$ 卷积层,后接两路 $1 \times 1$ 卷积层的形式。
2.1.1. 锚点
在滑窗的每一个位置,同时预测最多 $k$ 个候选框。由此 reg 层输出 $k$ 个矩形框共计 $4k$ 个坐标;cls 层输出 $2k$ 个分数,估计候选区域内是否有目标的概率(这里使用了 softmax,因此有两个概率值,对应有和没有两种情况;也可以使用 logistic 回归来得到 $k$ 个分数)。
每个候选区域定义为其相对于一个参考框(reference box)的偏移,这个参考框称为锚点(anchor)。每个锚点框的中心在滑窗的中心,具有不同的尺寸和长宽比。文章中默认使用 $3$ 种尺寸和 $3$ 种长宽比,共有 $k = 9$ 个锚点框。对于尺寸为 $W \times H$(通常约 2400)的特征图,共有 $WHk$ 个锚点框。
由于 reg 和 cls 两个全连接层在所有位置上共享,使得这种方法具有平移不变性(translation-invariant),同时参数量很少。对于 $k = 9$ 的情况,reg 和 cls 的输出的尺寸只有 $(4 + 2) \times 9$,对于 VGG-16 网络,参数量只有 $512 \times (4 + 2) \times 9 = 2.8 \times 10^4$。
相比 Figure 1a 中使用图像/特征金字塔,或者 Figure 1b 中多尺寸的滑窗,Faster R-CNN 使用的方法基于锚点框金字塔,以不同尺寸和长宽比例的锚点框作为参考,只需单一尺寸的输入图像和特征图,并在在特征图上使用单一尺寸的过滤器,更加高效。
2.1.2. 代价函数
训练 RPN 时,为每个锚点框赋予一个二值标签,表示区域内是否有目标。如果锚点框满足以下两个条件之一,则标记其为正例:
- 对某个标注框,该锚点框与之具有最大 IoU;
- 锚点框与某个标注框的 IoU 大于 0.7。
对于一个标注框,可能会有多个锚点框满足上述条件,并被标记为正例。通常来说使用第二个条件就已经足够了,但在极少的情况下有些标注框没有满足第二个条件的锚点框,此时通过第一个条件标记锚点框。如果锚点框与所有标注框的 IoU 都低于 0.3,则标记其为负例。
文章对 RPN 使用了 Fast R-CNN 中的多任务损失
$$
\begin{aligned}
L(\{p_i\}, \{t_i\}) &= \frac{1}{N_{cls}} \sum_i L_{cls}(p_i, p_i^*) \\
& + \lambda \frac{1}{N_{reg}} \sum_i p_i^* L_{reg}(t_i, t_i^*)
\end{aligned} \tag{1}
$$
其中 $i$ 为小批量中锚点的索引,$p_i$ 是预测锚点 $i$ 为目标的概率,$p_i^*$ 为锚点框的标签($1$ 为正例,$0$ 为负例)。$t_i$ 为预测的边界框,$t_i^*$ 为与锚点 $i$ 关联的标注框,二者都是长度为 4 的向量,表示框的坐标。$L_{cls}$ 为有/无目标的分类对数损失。$p_i^* L_{reg}$ 表示只对正例启用 $L_{reg}$ 损失,负例(背景)没有标注框。
式 $(1)$ 中的 $\lambda$ 用于平衡两个损失,对于文中的场景,有 $N_{cls} = 256$,$N_{reg} \sim 2400$,文章设置 $\lambda = 10$,使得两个损失的权重大致相等。文章通过实验发现模型性能对 $\lambda$ 不敏感,当 $\lambda$ 在 1 到 100 这两个数量级间变动时,对 mAP 只有约 1% 的影响,当 $\lambda = 10$ 时获得了最高 mAP。
式 $(1)$ 中的 $L_{reg}(t_i, t_i^*) = R(t_i – t_i^*)$,定义同 Fast-RCNN 的 $\mathrm{smooth}_{L_1}(x)$,即
$$
R(x) = \mathrm{smooth}_{L_1}(x) =
\begin{cases}
0.5 x^2 & \text{if } |x| < 1 \\
|x| – 0.5 & \text{otherwise}
\end{cases}
$$
注意以上仅为 RPN 部分的损失。
边界框回归使用了 R-CNN 中的形式
$$
\begin{aligned}
t_x &= (x – x_a) / w_a, \qquad & t_y = (y – y_a) / h_a \\
t_w &= \log(w / w_a), \qquad & t_h = \log(h / h_a) \\
t_x^* &= (x^* – x_a) / w_a, \qquad & t_y^* = (y^* – y_a) / h_a \\
t_w^* &= \log(w^* / w_a), \qquad & t_h^* = \log(h^* / h_a) \\
\end{aligned} \tag{2}
$$
其中 $x, y, w, h$ 分别为边界框的中心坐标和宽高,$x, x_a, x^*$ 分别表示预测框、锚点框和标注框。上面的方法将标注框回归到标注框。
2.1.3. 训练 RPN
可以使用随机梯度下降(SGD)通过反向传播来训练 RPN,构造小批量时,在一张图像的众多锚点中进行采样 256 个锚点,并使得正例和负例的比例为 $1:1$,如果正例数量少于 128,则用负例补充。
2.2. 在 RPN 和 Fast R-CNN 间共享特征
Faster R-CNN 中包含 RPN 和 Fast R-CNN 检测器两个网络,二者共享部分卷积特征。文章给出了三种训练方法:
- 交替训练(alternating training):先训练 RPN,然后用得到的候选区域训练 Fast R-CNN,再用调整后的 Fast R-CNN 初始化 RPN,迭代进行。文章的实验中使用了此种方法。
- 近似联合训练(approximate joint training):将 RPN 和 Fast R-CNN 合并为一个网络,如 Figure 2 所示。前向传播时,先由 RPN 生成候选区域,然后把这些区域看作固定的、预计算的输入来训练 Fast R-CNN 检测器。反向传播时,共享层会整合两个网络的传播信号。这个方法容易实现,但训练 Fast R-CNN 时将输入的候选框作为固定数据,忽略了对候选框坐标的梯度。
- 非近似联合训练(non-approximate joint training):训练 Fast R-CNN 时输入的候选框是由 RPN 从输入图像预测得到的,可以将 RPN 生成的候选框看成是输入的函数。反向传播时,也要考虑对候选框坐标的梯度,这要求 Fast R-CNN 中的 RoI 池化要能对候选框坐标可微。
文章使用了 4 步交替训练:
- 训练 RPN,使用 ImageNet 预训练权重作为初始化;
- 使用第 1 步生成的候选框训练 Fast R-CNN 检测器,此时训练的 Fast R-CNN 是一个单独的网络,使用 ImageNet 预训练权重作为初始化,不与 RPN 共享卷积层;
- 使用检测器网络初始化 RPN,固定共享的卷积层,只对 RPN 独有的层进行微调,此时两个网络共享卷积层;
- 固定共享的卷积层,对 Fast R-CNN 独有的层进行微调。
由此训练了共享卷积层的两个网络。文章指出,虽然可以再按此流程迭代多次,但提升很少。
2.3. 实现细节
文章将输入图片的较短边缩放到 $s = 600$ 像素,使用单尺度图像对 RPN 和检测网络进行训练和测试。文章指出,使用图像金字塔进行多尺度特征提取可能会提高准确度,但成本过高,难以达到较好的速度-准确度取舍。对于 ZF 和 VGG 网络,最后一个卷积层的步长为 16 像素,虽然步长较大,但仍获得了很好的效果;降低步长则还可能进一步提高准确度。
文章使用了 $128^2$、$256^2$、$512^2$ 三种不同面积,以及 $1:1$、$1:2$、$2:1$ 三种不同比例的锚点框,这些选择并不针对特定数据集。通过锚点框可以检测不同尺寸和比例的对象(如 Figure 3 右图)。注意对边界框的预测可能会大于感受野,因为即便只能看见目标的中心部位,仍可以大概推测出目标的范围。
对于范围超过了图像边界的锚点框,训练时会进行忽略,不贡献损失。对于 $1000 \times 600$ 尺寸的图像,通常会有约 $20000$($\approx 60 * 40 * 9$)个锚点框,忽略跨越图像边界的锚点框后,每张图大约剩下 $6000$ 个锚点框用于训练。如果在训练时不忽略这些锚点框,则会引入较大的、难以修正的误差项,使得训练无法收敛。测试时,会在整张图像上进行 RPN,这一步可能会产生超过图像边界的候选框,只需对它们进行裁剪,对齐到图像边界。
RPN 生成的部分候选区域会有重叠,为了降低冗余,文章使用了 NMS 对候选区域进行过滤。通过固定 NMS 的 IoU 门限为 0.7,每张图像只会保留约 2000 个候选区域。NMS 本身不会影响检测准确度,但会显著降低候选区域的数量。NMS 之后,再选择其中 top-N 的候选区域进行检测。文章在训练时使用了 2000 个 RPN 候选区域。
3. 实验结果
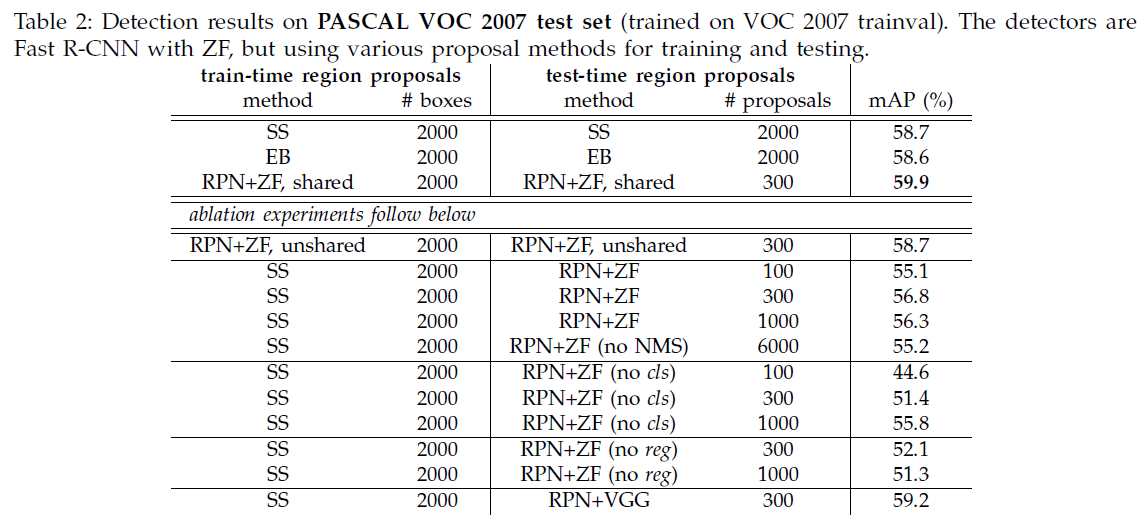
文章在 VOC 2007 上比较了使用不同方法生成候选区域的性能,如 Table 2 所示。可见 Faster R-CNN(RPN+ZF, shared)只用 300 个候选框就获得了 59.9 的最高 mAP。
针对 RPN,文章实验了以下场景:
- 不共享卷积:RPN+ZF, unshared 在训练到第 2 步时停止,两个网络没有共享卷积层,mAP 为 58.7,差于共享卷积。
- 在训练时不使用 RPN:在训练时使用 SS,测试时使用 RPN(不共享卷积),mAP 在 55 到 56 附近,这是因为训练和测试时的候选框不一致。注意即便在测试时只用 100 个候选区域,也达到了 55.1 的 mAP,说明 RPN 生成的头部候选区域足够准确。RPN+ZF (no NMS) 没有 NMS,使用了 6000 个候选区域,mAP 为 55.2,说明 NMS 不会影响性能。
- 不使用 RPN 的 cls:测试时删除 RPN 的 cls 层,随机从候选区域中采样 $N$ 个,可见 mAP 随 $N$ 的降低快速下降。
- 不使用 RPN 的 reg:测试时删除 RPN 的 reg 层,使用锚点框作为候选区域,使用 300 个候选区域时 mAP 下降到 52.1,可见通过 reg 回归可以提高候选框的准确度,仅使用锚点框不足以进行准确的检测。
- 在 RPN 中使用更大的网络:文章尝试了在 RPN 使用 VGG,使用 300 个候选区域时,RPN+VGG 获得了 59.2 的 mAP,相比 RPN+ZF 的 56.8 有所提升。
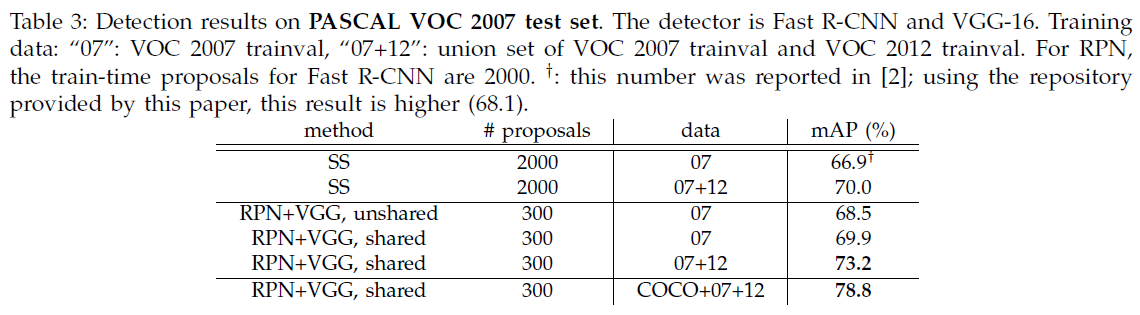
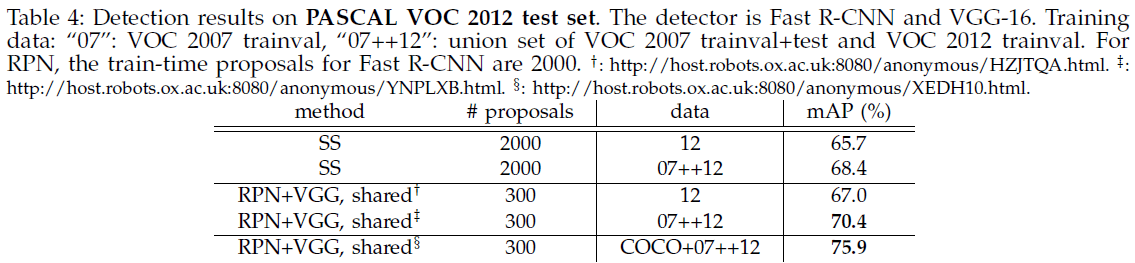
文章进一步试验了使用 VGG-16 在 VOC 2007 和 VOC 2012 的性能,如 Table 3、Table 4 所示。
Faster R-CNN 测试时的速度如 Table 5 所示。
