[Reading] YOLOv3: An Incremental Improvement
YOLOv3: An Incremental Improvement (2018/4)
1. 概述
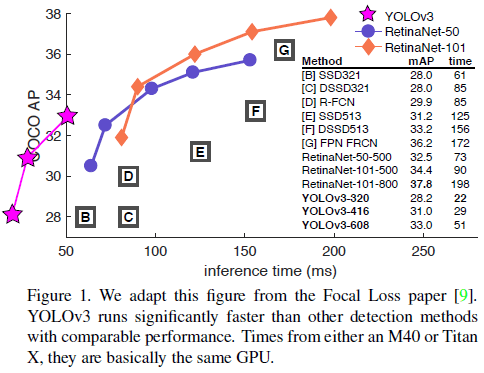
文章进一步对 YOLO 进行了改进,提出的 YOLOv3 稍微增大了模型体积,让模型更加准确,同时保证了速度。
2. 改进
2.1. 边界框预测
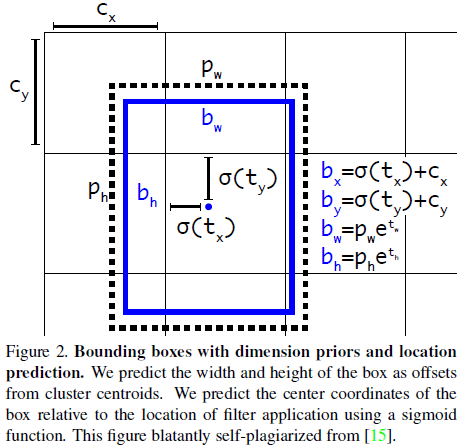
YOLOv3 的边界框预测方法和 YOLO9000 相同,使用维度聚类找到了一系列锚点框,通过预测 $t_x, t_y, t_w, t_h$,得到目标的边界框 $b_x, b_y, b_w, b_h$,如 Figure 2 所示。
$$
\begin{aligned}
b_x &= \sigma(t_x) + c_x \\
b_y &= \sigma(t_y) + c_y \\
b_w &= p_w e^{t_w} \\
b_h &= p_h e^{t_h}
\end{aligned}
$$
其中 $(c_x, c_y)$ 为负责预测的网格单元相对于图像左上角的偏移,$p_w, p_h$ 为锚点框的宽和高。
YOLOv3 为每个边界框预测一个 objectness 分数。与标注框重合最高的锚点框的 objectness 分数为 1;对于其余与标注框重合的锚点框,如果标注框和锚点框的 IOU 大于特定门限(文章选择 $0.5$),则忽略该预测。每个标注框只对应一个锚点框。对于没有分配标注框的锚点框,只计算 objectness 损失,不计算定位和分类损失。
2.2 类别预测
在预测边界框的类别时,使用多个独立的 logistic 分类器进行多标签预测,以便于利用如 Open Images Dataset 这种标签有重叠的数据集。如女人和人这两个概念是有重叠的,使用 softmax 会认为每个边界框只有一个类别。
2.3. 多尺度预测
YOLOv3 会在 3 种不同的尺度上预测边界框,每个边界框对应一个 3 维张量,包含边界框、objectness 和类别预测。文章在 COCO 上的输出尺寸为 $N \times N \times [3 * (4 + 1 + 80)]$,每个尺度预测 3 个框,每个框包含 4 个坐标,1 个 objectness 和 80 个类别预测。
如 What’s new in YOLO v3? 给出的图例所示
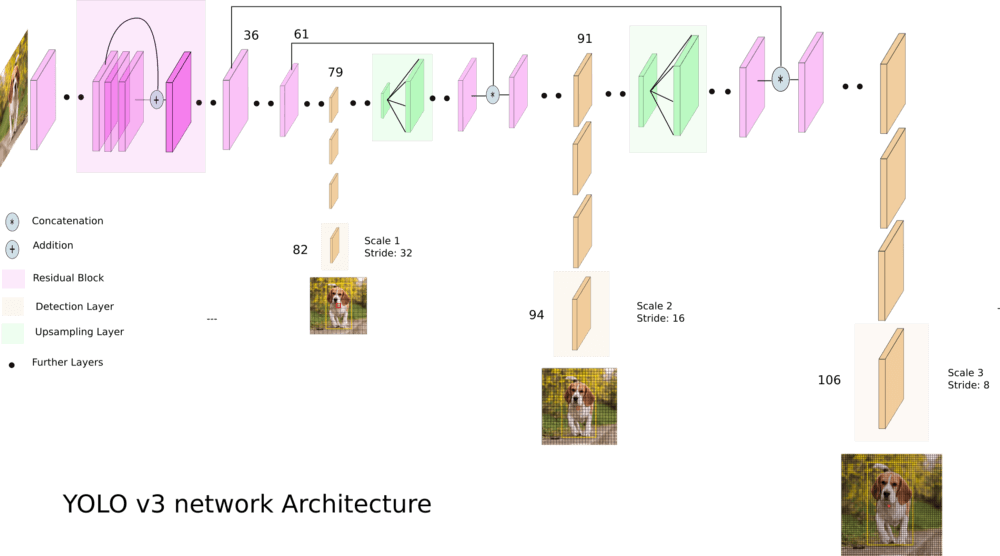
- 第一个尺度的预测位于第 82 层。
- 然后第 79 层的特征图经过上采样,与第 61 层的特征图拼接,在第 94 层给出第二个尺度的预测。
- 类似地,第 91 层的特征图经过上采样,与第 36 层的特征图拼接,在第 106 层给出第三个尺度的预测。
通过多尺度的预测,可以从前面的层中获得更细粒度的特征,但网络也变得更大。
2.4. 特征提取
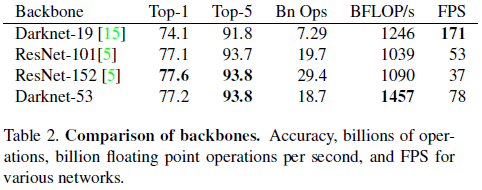
文章结合残差网络,提出了用于特征提取的 Darknet-53,结构如 Table 1 所示。
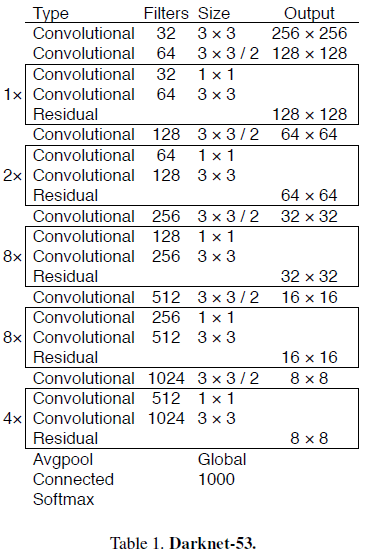
Darknet-53 具有高于 Darknet-19 的性能和高于 ResNet-101 和 ResNet-152 的效率,如 Table 2 所示。
3. 实验结果
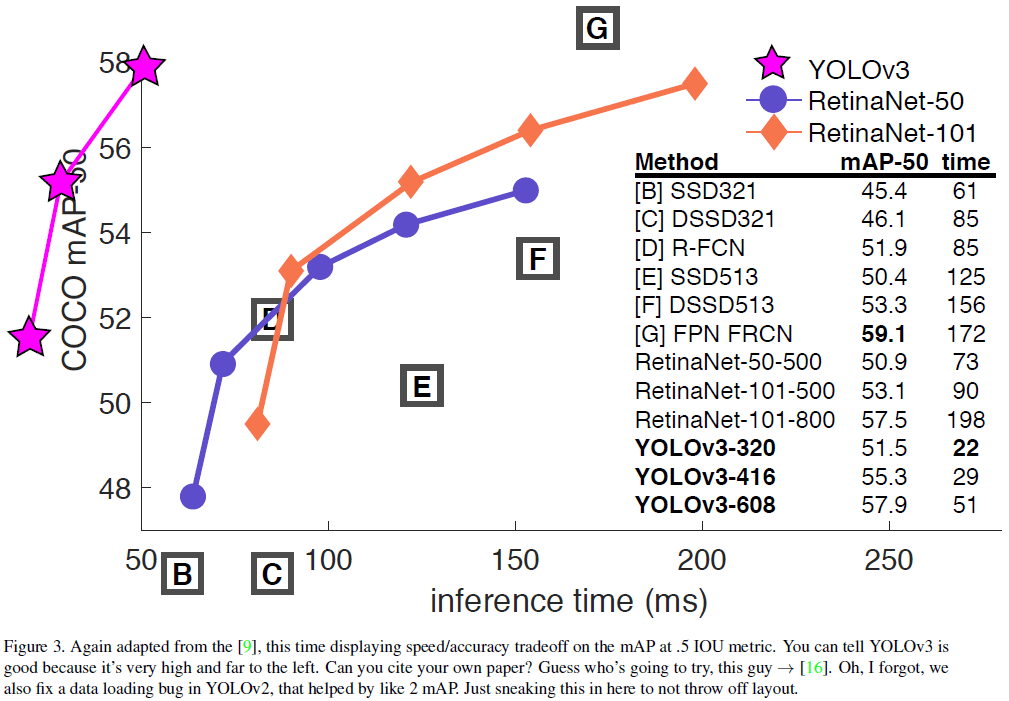
文章给出了 YOLOv3 在 COCO 上的性能如 Table 3 所示,其 mAP 和 SSD 接近,但速度是后者的 3 倍。YOLOv3 在 $AP_{50}$(IOU = 0.5)上的性能很好,几乎达到了 RetinaNet 的水平,说明 YOLOv3 能够很好地预测边界框。而随着 IOU 门限的提升,YOLOv3 的性能快速下降,说明 YOLOv3 难以让边界框与物体完美对齐。
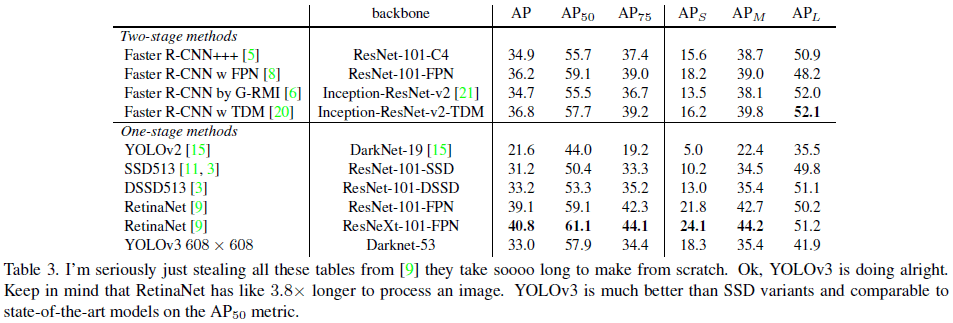
此外,之前的 YOLO 不擅长检测小物体,YOLOv3 通过引入多尺度预测,获得了较高的 $AP_S$,但相比之下在中型和大型物体上的性能欠佳。
4. 无效的方法
文章还尝试了使用不同的锚点框偏移预测方式,使用线性激活函数替代 logistics 预测 $x, y$,使用 focal loss、使用双 IOU 门限等方法,都没有带来提升。