[Reading] Very Deep Convolutional Networks For Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition (2014/9)
1. 概述
文章的主要贡献有:
- 验证了通过增加卷积网络深度,可以显著提升其在图像识别任务上的准确率。文章评估了一系列具有不同数量 $3 \times 3$ 卷积层的网络,发现具有 16~19 层的网络具有最佳性能。
- 提出了一种构建深度网络的基本规则,并据此构建了 VGG 系列网络。 VGG 网络并没有使用什么特殊的结构,只是在经典卷积网络的基础上增加的深度,就可以达到当时的最佳性能。
- 此外文章还指出,训练时网络权重的初始化非常重要。对于所提出的 5 种不同深度的网络 A~E,文章先通过随机初始化训练了最浅的网络 A,然后用它来初始化其他更深的网络。
2. 设计思路
2.1. 基本规则
文章给出了一种构建网络的基本规则:主要使用 $3 \times 3$ 的卷积,步长为 1,通过 padding 使输入和输出的分辨率保持一致。 使用 $2 \times 2$ 的最大池化,步长为 2,使得输入分辨率减半。网络末端使用若干个全连接层,最后通过 softmax 进行分类。所有隐藏层都使用 ReLU 作为激活函数。
2.2. 卷积核尺寸
文章之前的高性能网络通常使用较大尺寸的卷积核,例如 $11 \times 11$、$7 \times 7$、$5 \times 5$ 等,而本文则使用了较小的 $3 \times 3$ 卷积核。两个 $3 \times 3$ 卷积叠加的感受野相当于一个 $5 \times 5$ 卷积,三个 $3 \times 3$ 卷积叠加的感受野相当于一个 $7 \times 7$ 卷积,虽然感受野相同,但使用多个 $3 \times 3$ 卷积叠加会带来两个好处:一方面,多个 $3 \times 3$ 卷积层包含更多的非线性,有助于提高区分能力。另一方面,多个 $3 \times 3$ 卷积叠加的参数量要大幅少于直接使用大尺寸卷积,例如 $3$ 个 $3 \times 3$ 卷积(通道数为 $C$)的参数量为 $3(3^2C^2) = 27C^2$,而一个 $7 \times 7$ 卷积的参数量为 $7^2C^2 = 49C^2$;因为参数更少,可以将 $3$ 个 $3 \times 3$ 卷积看成是给 $7 \times 7$ 卷积加上了正则化,相当于强制 $7 \times 7$ 卷积可以分解为 $3$ 个 $3 \times 3$ 卷积。
除了 $3 \times 3$ 卷积,文章中还使用了 $1 \times 1$ 卷积。$1 \times 1$ 卷积本身是一个线性映射,通过加入非线性的激活函数,$1 \times 1$ 卷积层可以在不改变感受野的同时增加非线性。
3. 网络架构
文章基于上面的构建规则,给出了一组不同深度的网络,如 Table 1 所示。几种网络都使用了大量 $3 \times 3$ 卷积层,间或加入最大池化层。每经过一次池化,特征图的长和宽减半,通道数翻倍。其中第二列中的 LRN 指局部响应归一化(local response normalization),文章通过实验得知,LRN 在 ILSVRC 数据集上并没有带来性能提升。
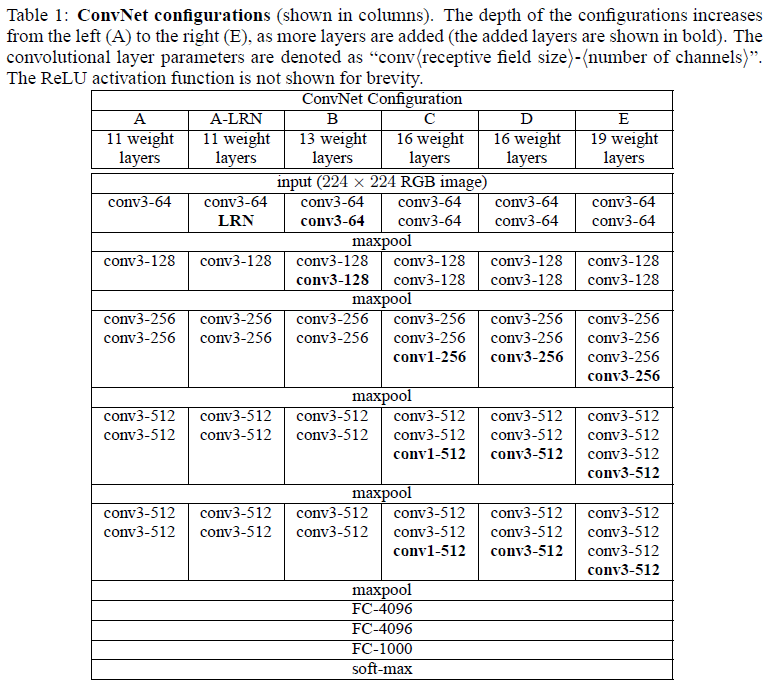
Table 2 列出了这些网络的参数量,可见虽然网络的深度从 11 层逐渐增长到 19 层,网络的参数量却没有大幅增加。

文章指出,在训练时网络权重的初始化非常重要,不良的初始化会让深度网络的梯度变得不稳定,从而使学习停滞。文章首先使用随机初始化训练了较浅的网络 A,然后使用网络 A 的权重来初始化其他更深的网络,包括前四个卷积层和后三个全连接层。
4. 实验结果
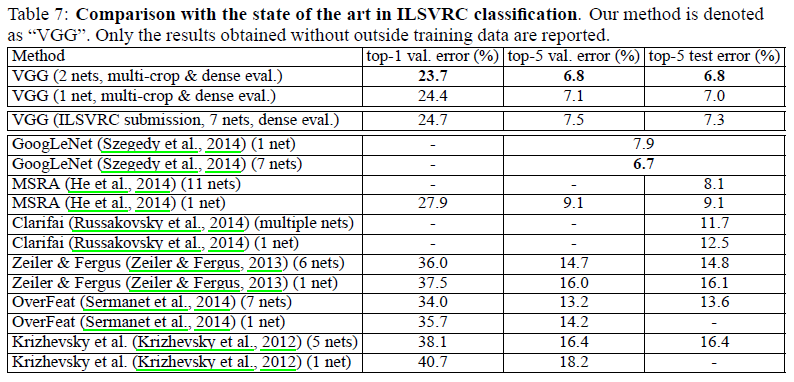
文章给出了网络在 ILSVRC-2014 中的性能如 Table 7 所示(队伍名称为 VGG)。可见 VGG 的性能大幅超越了往年的最佳网络,和当年最佳的 GoogLeNet 接近。如果只考虑单网络的性能,VGG 具有最佳的性能。