[Reading] Going Deeper with Convolutions
Going Deeper with Convolutions (2014/9)
1. 概述
文章的主要贡献有:
- 提出的 Inception 模块通过组合多种卷积和池化,增加网络深度和宽度,同时通过 $1 \times 1$ 卷积进行压缩来减少计算,在大幅提高性能的同时控制计算量。
- 通过堆叠 Inception 模块得到的 Inception 网络(GoogLeNet)在当时的图像识别和检测任务上达到了 SOTA 性能。
- 文中提出的找到一个局部最优的卷积结构,然后重复使用,构建出整个网络架构的方式,在之后也有很多应用。
- 由于网络很深,为了提高梯度反向传播的效率,在训练时使用了两个额外的分支,使用中间特征进行预测。
- 证明了使用已有的密集构造块来近似最优的稀疏结构,是提高神经网络在计算机视觉上性能的可行手段。
在传统的卷积神经网络中,通常使用若干个卷积层后跟若干个全连接层的结构。通过增加深度和宽度可以获得更大的网络,通常也能获得更好的性能,但这样做会带来两个问题:一方面,更大的模型具有更多的参数,更容易过拟合;另一方面,更大的模型需要消耗更多的计算资源,而实际场景中计算资源总是有限的。对于这两个问题,一个基本的解决方法是将全连接层替换为稀疏连接的结构,但在实际中,各种计算框架都有多种优化来高效地进行密集矩阵的计算,而对稀疏矩阵的计算效率较低。
针对以上问题,文章希望通过密集计算的方式来近似一种局部最优的稀疏卷积网络结构。具体方法是,找到一个局部最优的卷积结构,然后重复使用,构建出整个网络架构。
2. 网络架构
2.1. Inception 模块
在设计卷积网络时,会面临很多选择,例如使用什么样的层结构,使用多大的过滤器尺寸。文章提出的 Inception 模块同时使用了 $1 \times 1$、$3 \times 3$、$5 \times 5$ 的卷积,以及一个最大池化,如 Figure 2(a) 所示。这些模块的输出连接在一起,作为 Inception 模块的输出,网络可以通过学习来决定如何使用这些层,不再需要人工进行选择。
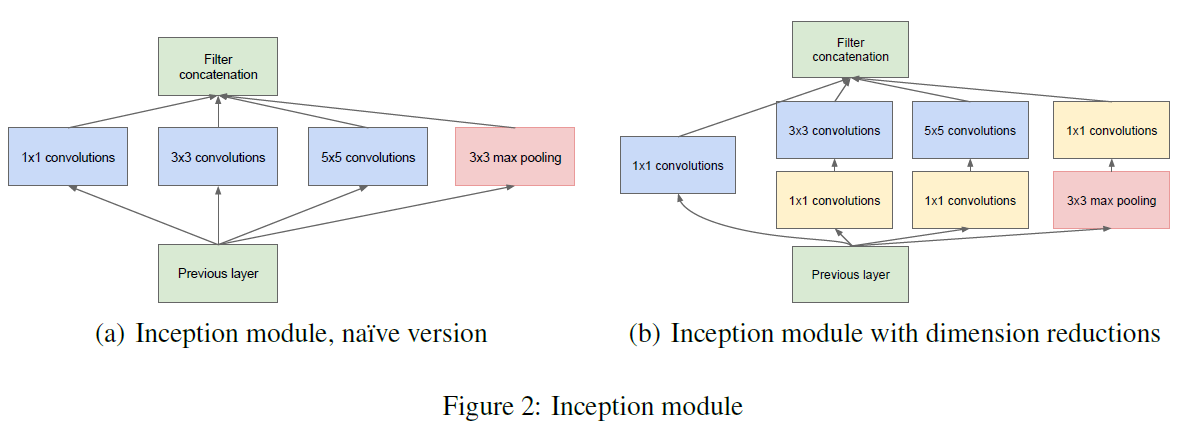
这样做带来的一个问题是 Inception 模块的计算量非常大,尤其是在叠加使用时,由于池化不改变通道数,再加上其他卷积的输出,导致每一层输出的数据量都比前一层大。解决这一问题的方法是使用维度压缩,通过额外的 $1 \times 1$ 卷积来降低 $3 \times 3$ 卷积、$5 \times 5$ 卷积和池化输出的通道数,如 Figure 2(b) 所示。这些额外的 $1 \times 1$ 卷积中使用了 ReLU 作为激活函数,来引入额外的非线性。
Inception 网络由 Inception 模块堆叠组成,中间偶尔使用步长为 2 的最大池化来降低分辨率。由于大量使用了压缩,Inception 网络可以在每个 stage 使用各种结构、增加网络的深度和 stage 的宽度,而不必担心计算量过大。
同时文章提到,由于内存效率等技术原因,网络的低层仍使用传统的卷积层,只在较高层使用 Inception 模块。这一限制并不必要,只是因为当时的实现效率不高。
2.2. GoogLeNet
文章给出了基于 Inception 的 GoogLeNet 网络结构如 Table 1、Figure 3 所示。

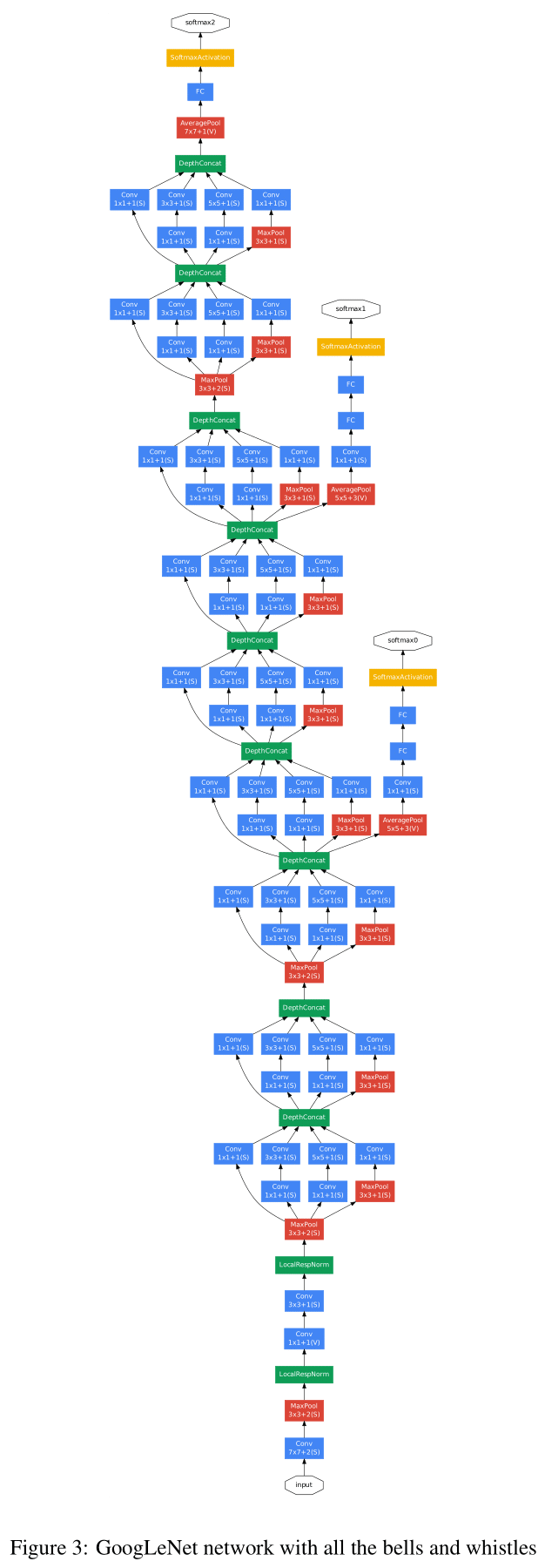
网络遵循了前述的构造规则,主要使用 Inception 模块堆叠而成,在若干组 Inception 模块之间通过最大池化降低分辨率。
因为网络很深,为了提高梯度反向传播的效率,网络中除了最后用于输出结果的 Softmax2,还在训练时添加了 Softmax0 和 Softmax1 两个分支。这两个分支获取了网络中隐藏层的输出并进行预测,确保网络中间的一些特征也足以进行一定程度的预测,提高反向传播的梯度信号,还能起到正则化的作用。在测试时,这两个分支就没有用了。
3. 实验结果
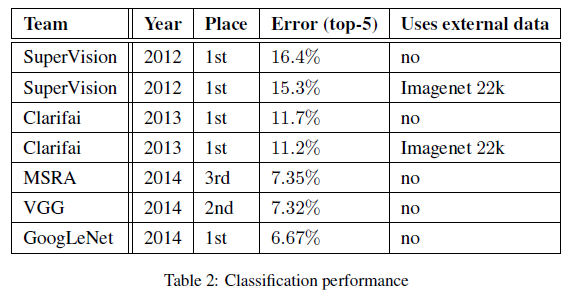
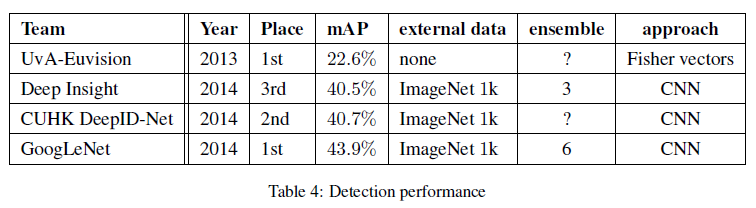
文章给出了 GoogLeNet 在 ILSVRC 2014 图像识别和检测比赛中的结果,如 Table 2 和 Table 4 所示,都取得了当时的最佳性能。