[Reading] Network In Network
Network In Network (2013/12)
1. 概述
文章的主要贡献有:
- 提出了 mlpconv 层结构,使用多层感知机来对感受野内的数据进行抽象,提升过滤器对局部图块的建模能力。这种结构相当于 $1 \times 1$ 卷积,在后来得到了广泛应用。
- 在进行分类时使用全局平均池化替换全连接层,起到了正则化的效果,避免了过拟合,同时建立起特征图和分类置信度间的关系,具有更好的可解释性。
- 使用 mlpconv 层和全局平均池化构造了用于图像识别的 Network In Network(NIN)网络结构,增强了对感受野内局部图块的区分能力,在当时的各种图像识别任务上都获得了 SOTA 性能。
传统的卷积层中的过滤器本质上是一个广义线性模型(generalized linear model,GLM),隐式地假设了要区分的概念是线性可分的,同一概念的不同表现形式都位于 GLM 所表示的区分平面的一侧。但实际上,数据中相同的概往往存在于非线性的流形(manifold)上,需要使用高度非线性的函数来捕获。因此文章希望通过将 GLM 替换为更加有效的非线性函数,来增强模型的抽象能力。
NIN 将 GLM 替换为一个微型网络,文中使用多层感知机(multilayer perceptron,MLP),得到了称为 mlpconv 的层结构,如 Figure 1 所示。类似于线性卷积层,mlpconv 层也将局部感受野映射为一个特征向量,通过在输入的特征图上滑动,得到输出特征图。滑动过程中,mlpconv 中的 MLP 在所有的位置上共享权重。NIN 的架构就是通过堆叠 mlpconv 层得到的。
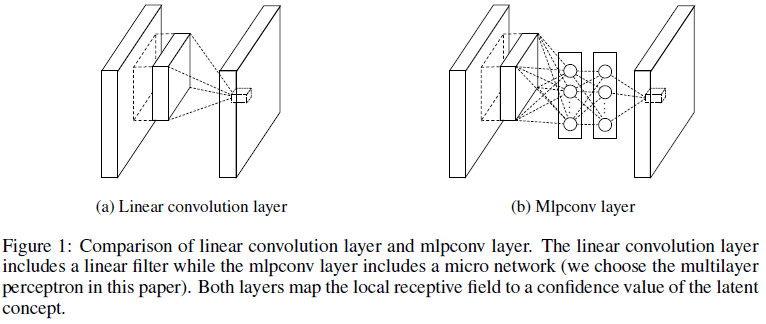
在通过 NIN 强化了网络的局部建模能力之后,可以在网络末端输出的特征图上使用全局平均池化替代全连接层,来生成用于分类的向量。全局平均池化直接建立了特征图和分类的关系,具有更好的解释性,同时也更不容易过拟合。
2. 卷积神经网络
对于传统的卷积层,特征图的计算为
$$
f_{i,j,k} = \max (w_k^T x_{i, j}, 0) \tag{1}
$$
其中 $(i, j)$ 为特征图中像素的位置,$x_{i, j}$ 表示中心在 $(i, j)$ 的一个输入图块,$k$ 表示特征图的通道。这里使用了 ReLU 作为激活函数。
式 $(1)$ 所示的线性卷积无法对高度非线性的输入数据进行有效的抽象,虽然可以通过增加过滤器数量来提高区分能力,但这样会让网络变得更加复杂。在卷积神经网络中,更深层的过滤器具有更大的感受野,通过组合低层的概念来生成更高级的概念。文章认为,在生成高级概念之前,提高网络对局部图块的抽象能力有益于提高网络的性能。
3. 网络架构
3.1. MLP 卷积层
为了提高网络对局部图块的抽象能力,需要将卷积层中的 GLM 替换为更复杂的结构来进行特征提取。在缺少先验知识时,这一“更复杂的结构”需要是一个通用的函数近似器,如径向基网络和 MLP。文章选择了多层感知机,因为它可以通过反向传播进行训练,且其本身也可以是一个深度模型。通过将 GLM 替换为 MLP,得到了如 Figure 1 右图所示的 mlpconv 的层结构,其计算如下所示:
$$
\begin{aligned}
f_{i,j,k_1}^1 &= \max ({w_{k_1}^1}^T x_{i, j} + b_{k_1}, 0) \\
& \vdots \\
f_{i,j,k_n}^n &= \max ({w_{k_1}^n}^T f_{i, j}^{n-1} + b_{k_n}, 0)
\end{aligned} \tag{2}
$$
其中 $n$ 为 MLP 的层数,使用了 ReLU 作为激活函数。
式 $(2)$ 也可以看成是一种级联的跨通道参数化池化(cascaded cross channel parametric pooling),MLP 的每一层都可以看成是一个作用在通道维度上的池化层,计算特征图在位置 $(i, j)$ 上各通道的加权和。跨通道参数化池化也可以看成是 $1 \times 1$ 卷积,$1 \times 1$ 卷积在之后获得了广泛应用。
mlpconv 层的结构类于 maxout 层相似,maxout 层的特征图的计算为:
$$
f_{i,j,k} = \max\limits_m (w_{k_m}^T x_{i, j}) \tag{3}
$$
maxout 层保留线性函数输出向量中的最大值,构造了一个分段线性函数,可以表示任意凸函数。而 mlpconv 使用了通用的函数,具有更强的表示能力。
3.2. 全局池化
在进行分类前,传统的卷积网络会将最后一个卷积层的输出拉伸为一个向量,输入给全连接层,然后再通过 softmax 得到分类结果。卷积层负责特征提取,全连接层对提取到的特征进行分类。由于全连接层很容易过拟合,通常要使用 dropout 等方式进行正则化。
NIN 在分类时使用全局平均池化替换了全连接层:在最后一个 mlpconv 层的输出的特征图的每个通道上进行平均池化,得到一个向量,长度等于特征图通道数,然后将这个向量输入 softmax 进行分类。由此就直接建立起了特征图和类别的关系,对于最后的特征图,每个通道对应一个分类的置信度,特征图就相当于是置信度图,具有更好的可解释性。能这样做的原因在于,相比与传统卷积层中的 GLM,NIN 中使用的 mlpconv 层可以更好地拟合置信度图。全局平均池化汇总了空间上的全部信息,没有任何参数,既能更好地应对输入的空间变换,还可以避免过拟合。
3.3. NIN 结构
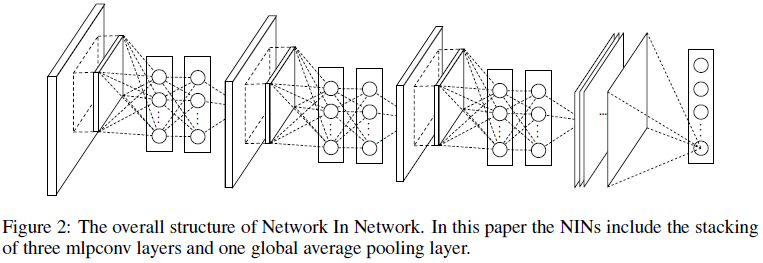
通过堆叠 mlpconv 层并在最后加上全局平均池化,就得到了 NIN 的结构。Figure 2 展示的 NIN 包含了 3 个 mlpconv 层,每个 mlpconv 中包含一个 3 层感知机。NIN 的层数和感知机的层数可以根据具体任务进行调整。
4. 实验结果
4.1. 网络性能
文章首先在 CIFAR-10 上验证了 NIN 的性能,如 Table 1 所示,可见 NIN 都达到了当时的最佳性能。

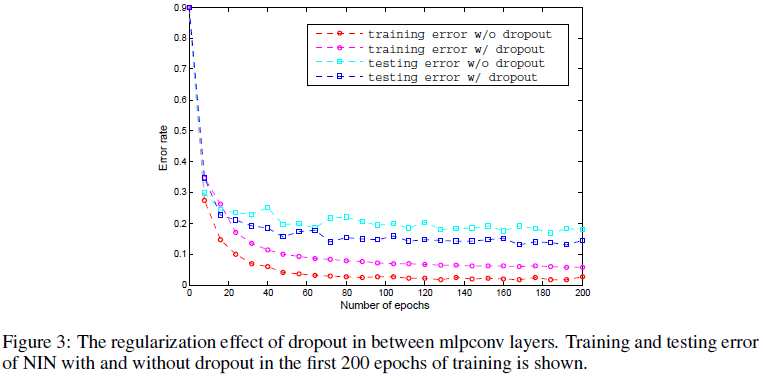
文章通过实验发现,在 NIN 的 mlpconv 层间使用 dropout 有助于进一步提升网络性能,由 Figure 3 可见,使用 dropout 的网络具有更低的 testing error。
NIN 在 CIFAR-100 上的性能如 Table 2 所示,可见 NIN 也取得了最低的错误率。

文章还在 Street View House Numbers(SVHN)数据集上进行了验证,识别真实场景的,结果如 Tabel 3 所示。

NIN 在 MNIST 上的性能如 Tabel 4 所示,可见 NIN 接近了最低的错误率。

4.2. 全局平均池化
为了验证全局平均池化的正则化效果,文章在 CIFAR-10 测试了如 Tabel 5 所示的不同组合的性能。可见没有 dropout 的全连接层效果最差,在全连接层上增加 dropout 降低了错误率,而使用全局平均池化的网络具有最低的错误率。

文章还进一步验证了全局平均池化在普通 CNN 上的正则化能力。在 CIFAR-10 数据集上,CNN 加全连接层的错误率为 17.56%,CNN 加全连接层和 dropout 的错误率为 15.99%,CNN 加全局平均池化的错误率为 16.46%。可见使用全局平均池化的错误率要低于全连接层,起到了一定的正则化作用,但全局平均池化的错误率略高于全连接层加 dropout。
4.3. 可视化
文章在 CIFAR-10 中选择了几个样本,对 NIN 最后一个 mlpconv 层的特征图进行了可视化,如 Figure 4 所示。可见在对应正确分类的特征图(对角线)中,对应输入图像中目标位置的区域具有较高的激活值,这是由全局池化保证的。虽然训练时只提供了分类信息,网络可以自己找到用于区分类别的区域和特征。
