[Reading] Feature Pyramid Networks for Object Detection
Feature Pyramid Networks for Object Detection (2016/12)
Contents
1. 概述
文章的主要贡献有:
- 提出了一种自顶向下、带有横向连接(lateral connection)的网络架构,可以在多个尺度上构建包含高级语义的特征图,称为特征金字塔网络(Feature Pyramid Network,FPN),显著提高了通用特征的提取能力。
- 将 FPN 用于 Faster R-CNN 后,网络在 COCO 检测任务上取得了当时的最佳性能,且在 GPU 上能保持 6 FPS 的速度。
在目标检测任务中,为了识别不同尺度的物体,通常的解决方法是在图像金字塔上构建特征金字塔(Figure 1(a))。特征金字塔具有尺度不变性,即物体尺度的变化可以看成是在金字塔不同层间的偏移。深度卷积网络虽然有能力学习更高级的语义,在一定程度上适应物体的尺度变化(Figure 1(b)),但仍可以从特征金字塔中受益,从而获得更高的准确度。特征金字塔的计算量和内存消耗较大,会大幅增加网络的推断耗时,且难以在内存中进行端到端地训练;如果只在测试时使用特征金字塔,又会导致训练和测试时的不一致。因此 Fast 和 Faster R-CNN 中并没有使用特征金字塔。
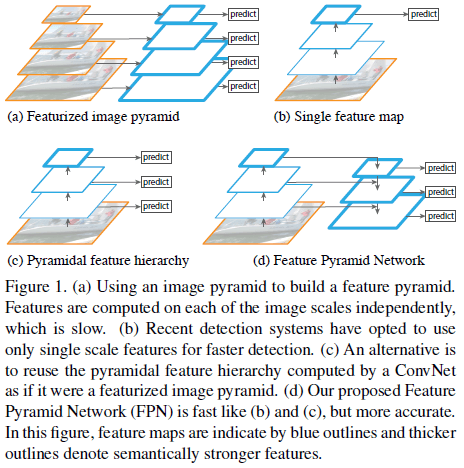
然而深度卷积网络本身就会逐层计算的不同层级的特征,通过下采样得到一系列不同分辨率的特征图,构成多尺度的金字塔形,但不同深度间的语义有较大差异,高分辨率特征图中的低级特征会影响对目标的识别。为解决此问题,SSD(Single Shot Detector)使用多个层级的特征图进行预测(Figure 1(c)),但为了避免使用低层特征,SSD 没有直接复用已有层的特征图,而是额外构建了一个金字塔,因此无法复用高分辨率的特征图,而高分辨率特征图对小物体的检测十分重要。
文章使用自顶向下的路径以及横向连接(lateral connection),将低分辨率、强语义的特征与高分辨率、弱语义的特征结合起来(Figure 1(d)),得到称为特征金字塔网络(Feature Pyramid Network,FPN)的结构。FPN 在利用卷积网络金字塔形特征层级的同时,使得金字塔能在所有层级都具有丰富的语义。
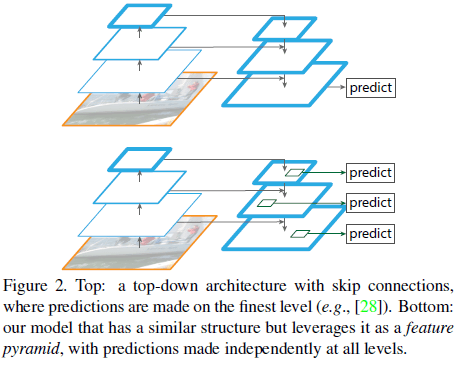
有一些网络中也使用了由上而下的结构(Figure 2 上图),但只在最后进行一次预测;相比之下 FPN 在每一层都进行独立的预测(Figure 2 下图)。
FPN 可以进行端到端地训练,并在训练和测试时使用,快速地从单分辨率图像中构造特征金字塔,提高目标检测和语义分割系统的性能。
2. FPN
FPN 使用单尺度的图像作为输入,以全卷积的形式,在不同层输出一系列尺寸成比例的特征图。这一过程与主干网络无关,文章使用 ResNets 作为主干网络。FPN 中包含一条自下而上的路径、一条自上而下的路径,以及横向连接。
2.1. 自下而上的路径
自下而上的路径指的是主干网络中的前向计算,由此得到一系列不同尺寸的特征图。网络中通常会有多个层输出相同尺寸的特征图,将这些层称为网络中的一个阶段(stage)。文章将每个 stage 作为一个金字塔层,选择 stage 中最后一层的输出作为金字塔中一层的特征图,因为每个阶段中最深的层具有最强的特征。
具体来说,对于 ResNet,使用每个 stage 中最后一个 residual block 的输出。记 conv2、conv3、conf4、conv5 的输出为 $\{C_2, C_3, C_4, C_5\}$,它们相对于输入图像的步长分别为 $\{4, 8, 16, 32\}$ 像素。这里没有使用 conv1,因为它占用的内存过大。
2.2. 自上而下的路径和横向连接
在自上而下的路径中,通过对空间上更稀疏、语义更强的金字塔的高层特征进行上采样,得到更高分辨率的特征,再通过横向连接,与自下而上的路径中具有更低层语义、包含更准确定位信息的特征联合起来。
如 Figure 3 所示,自上而下路径中更粗分辨率的特征进行 2 倍上采样,自下而上路径中的特证通过 $1 \times 1$ 卷积降低通道数,然后二者进行逐元素相加;最粗粒度的 $C_5$ 只进行 $1 \times 1$ 卷积来降低通道数。最后,在每个合并的特征图上进行 $3 \times 3$ 卷积,来降低上采样的混叠效应,最终得到对应 $\{C_2, C_3, C_4, C_5\}$ 的特征图 $\{P_2, P_3, P_4, P_5\}$。所添加的额外的层中没有使用非线性,文章发现是否使用非线性影响不大。
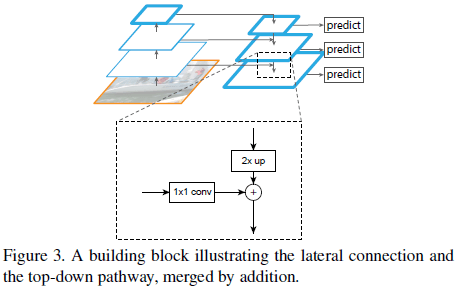
金字塔中所有层的特征都共享相同的分类器和回归器,因此所有层的特征图都具有相同的通道数 $d$,文章使用 $d = 256$。文章也尝试了在连接中使用更复杂的结构,但提升不大。
3. 应用
3.1. 用于 RPN
在 RPN 中可以使用 FPN 替换单尺度的特征图来进行分类和边界框回归,将 RPN 中用于分类和边界框回归的两个 head 加到 FPN 中每一层的特征之后,此时两个 head 会在特征金字塔每一层的所有位置上进行检测,也就不需要使用多尺度的锚点框了,每一层使用单一尺度的锚点框即可,如定义面积为 $\{32^2, 64^2, 128^2, 256^2, 512^2\}$ 的锚点框分别用于 $\{P_2, P_3, P_4, P_5, P_6\}$。同时不同长宽比例的锚点框仍是有必要的,如在每一层同时使用 $\{1:2, 1:2, 2:1\}$ 的锚点框,这样整个金字塔一共有 15 种锚点框。
训练时仍根据锚点框与标注框的 IOU 对锚点框进行标注。对于给定标注框,与之具有最大 IOU 的锚点框,以及 IOU > 0.7 的锚点框会被标记为正例。与所有标注框 IOU < 0.3 的锚点框会被标记为负例。注意在标注时并没有考虑金字塔的层级,而是通过 IOU 将标注框关联到锚点框,而锚点框位于金字塔特定的层级上。由此整合后的 RPN 仍可以像原 Faster R-CNN 中那样训练。
RPN 中的两个 head 会在所有位置共享参数,文章也尝试了不共享参数的方法,两种方法具有相似的准确率。这说明金字塔的所有层都具有相似的语义等级。
3.2. 用于 Fast-RCNN
Fast-RCNN 使用 RoI 池化来提取特征,在其中使用 RPN,要将宽度为 $w$、高度为 $h$ 的 RoI 以如下规则分配给特征金字塔的 $P_k$ 层:
$$
k = \lfloor k_0 + \log_2 (\sqrt{wh} / 224) \rfloor \tag{1}
$$
其中 $224$ 为 ImageNet 预训练的尺寸,$k_0$ 是面积为 $w \times h = 224^2$ 的 RoI 对应的层级。对于基于 ResNet 的 Faster R-CNN,设置 $k_0 = 4$。上式说明如果 RoI 的尺寸变小了(如变为 $224$ 的一半),则应被映射到更细粒度分辨率的层级(如 $k = 3$)。然后在所有层级的所有 RoI 上使用共享参数的预测 head 进行预测。
4. 实验结果
4.1. 使用 RPN 生成候选区域
为验证 FPN 在 RPN 中的作用,文章先使用 $C_4$ 和 $C_5$ 的单尺度特征图构建了两个 baseline,如 Table 1 中 (a)、(b) 所示,可见二者性能相似,说明使用单个高级的特征图并不足以提升性能,因为更高级的特征虽然具有更强的语义,但分辨率也更低。在 RPN 中使用 FPN 后,如 Table 1 (c) 所示,各项指标都有了大幅提升,对小目标的提升尤其大。
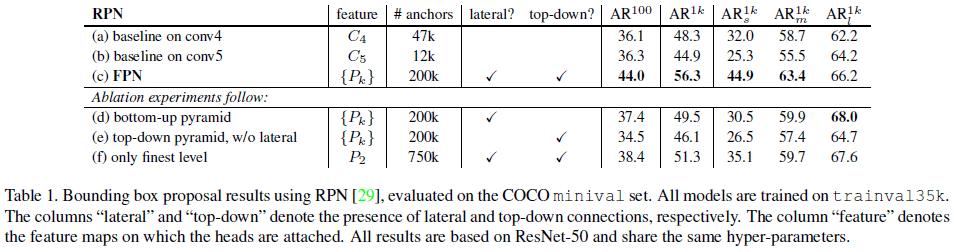
为验证 FPN 中自上而下路径的效果,文章尝试了只使用自下而上的路径,结果如 Table 1 (d) 所示,可见其性能与 (c) 有较大差距,文章猜想原因在于自下而上的金字塔中不同层级的语义间有较大的差距。
为验证横向连接的效果,文章尝试了没有横向连接的自上而下的 FPN,结果如 Table 1 (e) 所示,效果也很差,文章认为原因在于金字塔中的特征经过了多次下采样和上采样,缺少用于精确定位的特征。
为验证金字塔这种特征表示形式的效果,文章尝试了只使用具有最高分辨率和强语义的 $P_2$ 特征图,结果如 Table 1 (f) 所示,可见其效果优于 (a)、(b) 这两个 baseline,但仍差于 (c),因为使用多尺度的特征图有助于检测不同尺度的物体。另外文章发现由于 $P_2$ 的分辨率过高,使用 $P_2$ 时会得到更多的锚点框(750k),这同时说明仅使用更多的锚点框并不足以提升准确率。
4.2. Fast/Faster R-CNN 目标检测
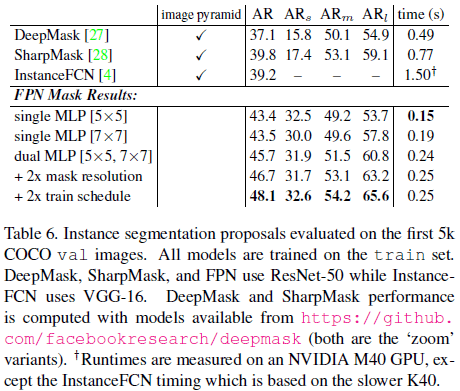
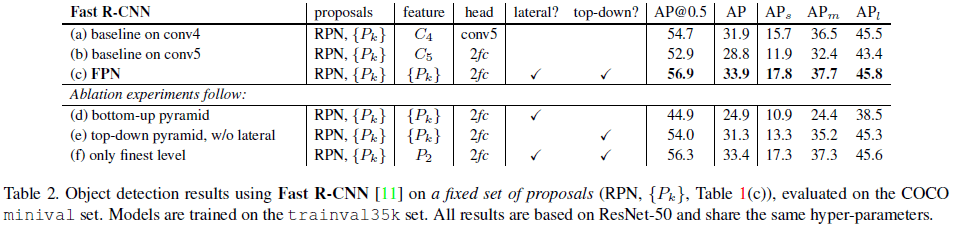
文章比较了在 Fast/Faster R-CNN 中使用 FPN 的效果如 Table 2、Table 3 所示,可见使用 FPN 都提高了网络性能。

4.3. 在 COCO 上的性能
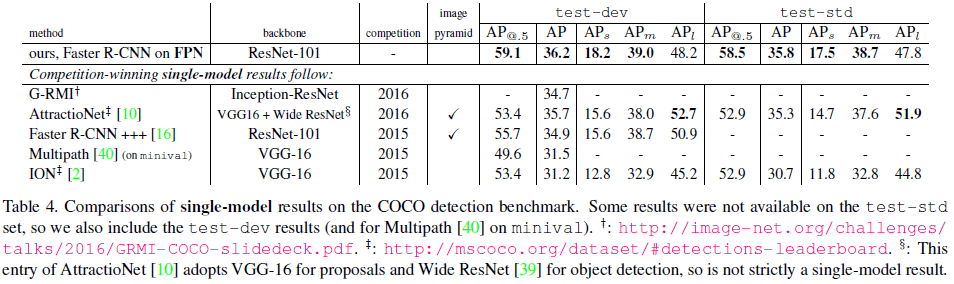
Table 4 比较了 FPN 在 COCO 上的性能,可见 Faster R-CNN on FPN 的单模型网络仅使用单尺度图像,就获得了最高的 AP。
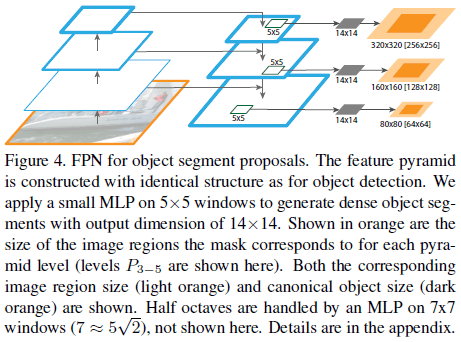
5. 扩展:Segmentation Proposals
通过在 FPN 的每一层使用一个 $5 \times 5$ 的 MLP 来预测一个 $14 \times 14$ 的 mask,FPN 也可以用于生成 mask proposal,如 Figure 4 所示。其用于分割任务的性能如 Table 6 所示。可见 FPN Mask 在获得更好性能的同时还具有更快的速度,使用更多、更大的 MLP 和更多的训练迭代还可以进一步提高性能。