[Reading] Fast R-CNN
Fast R-CNN (2015/4)
Contents
1. 概述
文章的主要贡献有:
- 提出了一种能够更高效地对候选区域中的目标进行分类的深度卷积神经网络,称为 Fast R-CNN(Fast Region-based Convolutional Network),使用了多种方法来提高训练/测试的速度和检测的准确度。
- 提出了 RoI(region of interest)池化,从特征图中为不同尺寸的候选区域提取固定长度的特征向量。对于一张输入图像上的不同候选区域,可以共享同一个特征图,在其上通过 RoI 池化提取特征向量,提高了计算效率。
- 基于 RoI 提取的特征,使用两个全连接层分别进行分类和边界框回归。训练时使用多任务损失,在一个微调阶段同时对分类和边界框回归进行优化,简化了训练流程。
- 提出了一种分级采样的方法来构造训练时使用的小批量数据,在一张图像上采样多个 RoI,每张图像中的 RoI 可以在前向和反向传播中共享计算和内存,提高了训练效率。
- 在全连接层上使用截断 SVD 来降低推断时的计算量。
R-CNN 使用卷积网络为候选区域进行分类,获得了很好的效果。但 R-CNN 也存在一些问题:
- 训练是多阶段的:在训练时,R-CNN 先要使用对数损失在候选区域上对卷积网络进行微调,再训练 SVM 对卷积网络输出的特征进行分类,最后还要学习对边界框进行回归来提高定位精度。
- 训练需要消耗大量的时间和存储空间:深度网络的训练非常耗时,输出的特征需要写入磁盘,占用大量的存储空间。
- 目标检测很慢:测试时需要对每一个候选区域进行特征提取,使用 VGG 在 GPU 上检测一张图片也需要 47s。
R-CNN 速度缓慢的原因在于,其中的卷积网络对每个候选区域独立地进行前向传播,没有共享计算。相比之下,SPPnet 会先计算整张输入图像的卷积特征图,然后通过最大池化来为每个候选区域提取特征,通过空间金字塔池化(spatial pyramid pooling,SPP)进行拼接,测试速度比 R-CNN 快 10 到 100 倍,训练速度也要快 3 倍。但 SPPnet 的训练仍是多阶段的,中间特征仍需要写到磁盘,且微调时无法更新空间金字塔池化前的层,使用固定的卷积层限制了使用更深网络时的性能。
文章提出的 Fast R-CNN 改善了 R-CNN 和 SPPnet 的不足,提升包括:
- 更高的检测质量(mAP)
- 使用多任务损失进行单阶段训练
- 训练可以更新网络中的所有层
- 不需要磁盘来缓存特征
使用 VGG16 时,Fast R-CNN 的训练和测试速度分别比 R-CNN 快 9 倍和 213 倍,同时还能在 PASCAL VOC 2012 上获得更高的 mAP。
Fast R-CNN 虽然大幅提高了测试速度,但仍然依赖外部的方法来生成候选区域(如 selective search),之后的 Faster R-CNN 通过将生成候选区的步骤整合进网络内部,进一步提高了检测效率。
2. Fast R-CNN 架构和训练
Fast R-CNN 的输入为一张图像和一组候选区域,整张图像通过若干个卷积层和池化层得到特征图,对于每一个候选区域,使用 RoI(region of interest)池化从特征图中提取一个固定长度的特征向量,每一个特征向量通过一系列全连接层的计算后,分为两路:一路使用 softmax 进行分类($K$ 个前景类别,再加 1 个背景类),一路为每个类别预测边界框(4 个实数),如 Figure 1 所示。

2.1. RoI 池化层
RoI 池化层使用最大池化将 RoI 内的特征转化为一个固定尺寸的小特征图,小特征图的尺寸 $H \times W$(如 $7 \times 7$)是与 RoI 尺寸无关的超参数。RoI 是一个矩形,由四值元组 $(r, c, h, w)$ 定义,其中 $(r, c)$ 为左上角坐标,$(h, w)$ 为高和宽。
RoI 池化会在 $h \times w$ 的窗口上使用 $h/H \times w/W$ 的子窗口进行最大池化,从而得到一个 $H \times W$ 的窗口。RoI 层可以看成是只使用一个金字塔层级的 SPP。
2.2. 使用预训练网络初始化
文章使用 ImageNet 预训练网络来初始化 Fast R-CNN。首先将网络的最后一个最大池化层替换为 RoI 池化层,RoI 池化输出尺寸 $H \times W$ 要和网络的第一个全连接层兼容(如 VGG 最后一个池化层输出特征图的尺寸为 $7 \times 7 \times 512$,则设置 ROI 的输出尺寸 $H = W = 7$)。然后将网络的最后一个全连接层和 softmax 替换为平行的两路全连接层,分别进行 $K + 1$ 个类别的预测,以及对每个类别边界框回归。最后修改网络接受图像列表和 RoI 列表两个输入。
2.3. 检测微调
2.3.1. 分级采样
SPPnet 中的 SPP 层对来自不同图像的 RoI 进行反向传播的效率很低,因为在网络末端,每个 RoI 虽然尺寸很小,但却具有很大的感受野,通常覆盖整张图像,涉及对整张图像的计算,也因此 SPPnet 在训练时不会对 SPP 之前的层进行更新。
为了提高训练效率,文章提出了一种分级采样的方法来构造小批量。首先采样 $N$ 张图像,然后再每张图像中采样 $R/N$ 个 RoI,每张图像中的 RoI 可以在前向和反向传播中共享计算和内存。$N$ 越小则每个小批量的计算量就越少,如使用 $N = 2$、$R = 128$ 时,每个小批量在 2 张图像上分别采样 64 个 RoI,比从 128 张图像上各提取 1 个 RoI 快 64 倍。
使用这种方法的一个潜在问题是同张图像中的 RoI 是相关的,可能会导致训练收敛缓慢,但实际中并没有出现这个问题,文章使用 $N = 2$、$R = 128$ 使用较 R-CNN 更少的迭代就获得了很好的效果。
除此之外,Fast R-CNN 将训练过程流水线化,在一个微调阶段同时优化 softmax 分类器和边界框回归器,而不是像 R-CNN 那样单独地对 softmax 分类器、SVM 和回归器进行训练。Fast R-CNN 的训练过程包含以下几个组成部分。
2.3.2. 多任务损失
Fast R-CNN 有两路输出,第一路通过对全连接层的 $K+1$ 个输出进行 softmax,为每个 RoI 输出用于分类的 $K + 1$ 个离散概率 $p=(p_0, \cdots, p_k)$;第二路为 $K$ 个类别中的每一类($k$)预测边界框的偏移量 $t^k = (t_x^k, t_y^k, t_w^k, t_h^k)$,偏移量的定义与 R-CNN 相同。
每个训练用的 RoI 都有一个真实类别 $u$ 和作为回归目标的标注框 $v$,定义使用多任务损失 $L$ 为
$$
L(p, u, t^u, v) = L_{\mathrm{cls}}(p, u) + \lambda [u \geq 1] L_{\mathrm{loc}}(t^u, v) \tag{1}
$$
其中分类损失 $L_{\mathrm{cls}}(p, u) = -\log p_u$ 为对真实类别 $u$ 的对数损失。对背景类定义 $u = 0$,艾佛森括号(Iverson bracket)$[u \geq 1]$ 在 $u \geq 1$ 即当前目标不是背景时为 $1$,否则为 $0$。背景类没有标注框,因此对背景类忽略定位损失 $L_{\mathrm{loc}}$。$L_{\mathrm{loc}}(t^u, v)$ 定义为
$$
L_{\mathrm{loc}}(t^u, v) = \sum_{i \in \{\mathrm{x}, \mathrm{y}, \mathrm{w}, \mathrm{h}\}} \mathrm{smooth}_{L_1} (t_i^u – v_i) \tag{2}
$$
其中 $t^u = (t_x^u, t_y^u, t_w^u, t_h^u)$ 为对类别 $u$ 的预测边界框,$v = (v_x, v_y, v_w, v_h)$ 为标注框。$\mathrm{smooth}_{L_1}$ 定义为
$$
\mathrm{smooth}_{L_1}(x) =
\begin{cases}
0.5x^2 & \text{if } |x| < 1 \\
|x| – 0.5 & \text{otherwise}
\end{cases} \tag{3}
$$
通过 $L_1$ 损失来降低对离群点的敏感度。
式 $(1)$ 中的 $\lambda$ 用于平衡两个任务的损失,文章将 $v_i$ 归一化为零均值和单位方差,并使用 $\lambda = 1$。
2.3.3. 小批量采样
如前所述,在使用 SGD 进行微调时,会从 $N = 2$ 张图像中,均匀采样 $64$ 个 RoI,得到尺寸为 $R = 128$ 的小批量。令其中 25% 的 RoI 与标注框的 IoU 至少为 $0.5$,这些 RoI 标注为前景类,即 $u \geq 1$。剩余的 RoI 与标注框的 IoU 在 $[0.1, 0.5)$ 区间,标注为背景类,即 $u = 0$。其中区间下界 $0.1$ 相当于难例挖掘的启发。训练时会以 $0.5$ 的概率对图像进行水平翻转,没有使用其他数据增强方法。
2.3.4. RoI 池化的反向传播
记输入 RoI 池化的第 $i$ 个激活值为 $x_i \in \mathbb{R}$,并记第 $r$ 个 RoI 的第 $j$ 个输出为 $y_{rj}$,则有 $y_{rj} = x_{i^*(r, j)}$,其中 $i^*(r, j) = \mathrm{argmax}_{i’ \in \mathcal{R}(r, j)} \; x_{i’}$,$\mathcal{R}(r, j)$
为 $y_{rj}$ 对应的最大池化输入的索引。一个 $x_i$ 可能被分配给不同的 $y_{rj}$,RoI 池化的反向传播会计算损失函数对于所有输入变量 $x_i$ 的偏导,即
$$
\frac{\partial L}{\partial x_i} = \sum_r \sum_j [i = i^*(r, j)] \frac{\partial L}{\partial y_{rj}} \tag{4}
$$
上式表明对小批量中的第 $r$ 个 RoI,如果 $i$ 被 $y_{rj}$ 对应的最大池化选中,则累积 $\frac{\partial L}{\partial y_{rj}}$。
2.4. 尺度不变性
文章尝试了暴力(brute force)学习和图像金字塔两种方法,来获得目标检测中的尺度不变性:前者将图像预处理到固定尺寸后进行训练和测试,网络必须从训练集中直接学习尺度不变性;后者则构造图像金字塔,训练时对每张图片随机选择一个尺度,测试时则使用全部尺度,由于 GPU 内存限制,文章只对较小的网络实验了多尺度训练。
3. Fast R-CNN 检测
使用 Fast R-CNN 进行目标检测时,将一张图像(或列表形式的图像金字塔)和 $R$(通常约 2000)个候选区域输入网络。对每一个 RoI $r$,通过前向传播可以得到类别的后验概率分布 $p$ 和一组相对于 $r$ 的边界框偏移量,每个类别都有自己的偏移量。对每个类别 $k$,使用 $\mathrm{Pr}(\mathrm{class} = k | r) \triangleq p_k$ 作为 $r$ 上的检测置信度,然后独立地对每个类别使用 NMS(non-maximum suppression)。
3.1. 截断 SVD
在 Faster R-CNN 中存在大量的 RoI,约一半的计算时间花在全连接层上。通过对全连接网络的权重进行截断 SVD,可以加快计算速度。对 $u \times v$ 的权重矩阵 $W$,近似分解为
$$
W \approx U \Sigma_t V^{\mathrm{T}} \tag{5}
$$
其中 $U$ 是一个 $u \times t$ 的矩阵,包含 $W$ 的前 $t$ 个左奇异向量;$\Sigma_t$ 是一个 $t \times t$ 对角矩阵,包含 $W$ 的前 $t$ 个奇异值;$V$ 是一个 $v \times t$ 矩阵,包含 $W$ 的前 $t$ 个右奇异向量。截断 SVD 将全连接层的参数量从 $uv$ 降低到 $t(u + v)$。据此将一个权重为 $W$ 的全连接层分解为一个权重为 $\Sigma_t V^{\mathrm{T}}$ 的线性全连接层,后接一个权重为 $U$ 的线性全连接层。
4. 实验结果
文章测试了 Fast R-CNN 在 VOC 2007、2010、2012 上的性能如 Table 1、2、3 所示,可见 Fast R-CNN 均获得了很好的效果。

文章比较了不同网络的训练和测试时间,如 Table 4 所示,可见 Fast R-CNN 大幅提升了训练和测试速度,同时还可以获得更高的 mAP。

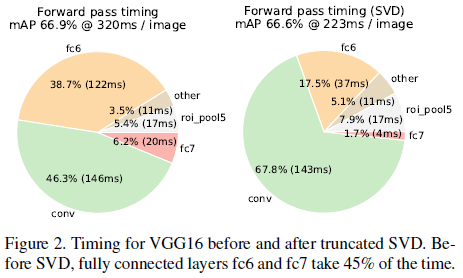
文章验证了截断 SVD 对速度的提升,如 Figure 2 所示,可见截断 SVD 降低了 30% 的检测时间(320ms 到 223ms),同时 mAP 只有略微下降(66.9% 到 66.6%)。
为了验证选择不同微调层数的影响,文章实验了不同的微调方式,如 Table 5 所示。可见 $\geq \mathrm{conv2_1}$ 获得了最高的 mAP。但这并不意味着应该微调所有的卷积层,卷积网络中的低层通常是通用的、与任务无关的,是否微调对结果影响不大。

5. 设计验证
5.1. 多任务训练
Fast R-CNN 通过多任务训练简化了训练流程,为了验证多任务训练对性能的影响,如 Table 6 所示,S、M、L 各组中:
- 第 1 列:令 $(1)$ 中的 $\lambda = 0$,只使用 $L_{cls}$ 训练得到一个基线网络(不含边界框回归)。
- 第 2 列:令 $(1)$ 中的 $\lambda = 1$,使用多任务损失训练,但在测试时禁用边界框回归,与第 1 列相比,可见使用多任务训练可以提高分类准确率。
- 第 3 列:使用分阶段训练和边界框回归,性能较不使用边界框回归有提升。
- 第 4 列:使用多阶段训练和边界框回归,性能优于第 3 列。

5.2. 尺度不变性
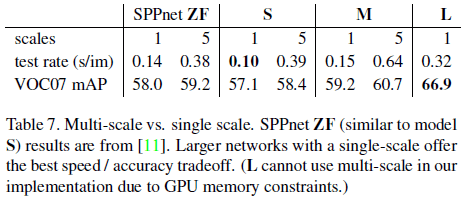
文章验证了 2.4. 中两种获得尺度不变性的效果,如 Table 7 所示。可见使用 5 种尺度可以获得更高的 mAP,但速度会降低。单尺度可以更好地平衡速度和准确率。
5.3. 使用 SVM 还是 softmax
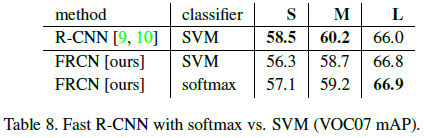
在对 RoI 进行分类时,Fast R-CNN 使用了 softmax,而 R-CNN 使用了 one-vs-rest 的线性 SVM。文章比较了这两种方法的性能,如 Table 8 所示。可见 softmax 的性能略优于 SVM,虽然 softmax 会在对 RoI 分类时在不同类别间引入竞争。
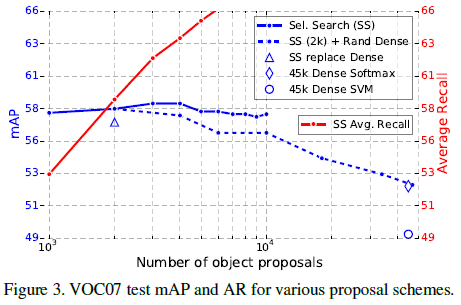
5.4. 候选区域数量
文章使用 selective search 的质量模式,测试了为每张图片生成 1k 到 10k 个候选区域时对 mAP 的影响,如 Figure 3 中蓝色实线。可见随着单张图片候选区域数量的增加,mAP 先上升后下降。固定单张图片的候选区域数量时,AR(Average Recall)和 mAP 通常具有较好的相关,但随着候选数量的增加,AR 会一直上升,如 Figure 3 中红线所示,说明由更多候选框带来的更高 AR 并不意味着会提升 mAP。