[Reading] ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks (2012)
1. 概述
文章的主要贡献有:
- 提出了一种用于图像识别任务的深度卷积神经网络(CNN),称为 AlexNet,在 ILSVRC-2012 比赛中以 15.3% 的 top-5 错误率夺得第一名,大幅优于第二名的 26.2%。展示了使用 CNN,仅通过监督学习就可以图像识别任务上获得破纪录的性能。
- AlexNet 中使用了一系列在当时非常新颖的结构和方法,如使用 ReLU 激活函数、多 GPU 训练、局部响应归一化(local response normalization,LRU)、重叠池化(overlapping pooling)等。
- 使用数据增强和 dropout 来降低过拟合。
- 文中的提出很多观点都对之后的相关研究产生了深远的影响,预示使用更多数据、更大网络、更长训练时间,可以获得更好的效果。
2. 网络架构
AlexNet 的网络架构如 Figure 2 所示。网络一共有 8 层,前 5 层为卷积层,后 3 层为全连接层,最后一个全连接层输出经过 softmax 进行分类。图中的网络的上下两部分分别位于两块 GPU 中,其中第 2、4、5 层都只与同 GPU 的上一层相连,第 3 层和全连接层则存在与上一层跨 GPU 的连接。前两个卷积层后使用了响应归一化;响应归一化和第 5 层后使用了最大池化。其中卷积层和全连接层都使用了 ReLU 激活函数。

注意图中第 1 层是一个 $11 \times 11$、步长为 $4$ 的卷积,输入尺寸标记为 $224 \times 224$,但实际上应为 $227 \times 227$,这样才能匹配下一层的尺寸 $(227 – 11) / 4 + 1 = 55$。
AlexNet 中使用了一系列新颖的方法,按重要性排列如下。
2.1. ReLU 激活函数
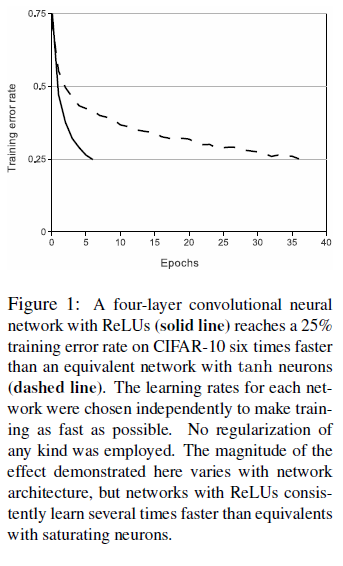
AlexNet 使用 ReLU 作为激活函数,即 $f(x) = \mathrm{max}(0, x)$ 。当时流行的 $f(x) = \mathrm{tanh}(x)$ 或 $f(x) = (1 + e^{-x})^{-1}$ 激活函数容易饱和,相比之下 ReLU 的训练速度要更快。文章比较了不同激活函数的训练速度如 Figure 1 所示,可见使用 ReLU 的网络达到 25% 训练错误率的速度比使用 tanh 的网络快 6 倍。
2.3. 多 GPU 训练
由于网络较大,单块 GPU 放不下,文章使用了两块 3GB 显存的 GTX 580,如 Figure 2 所示,网络被分成了上下两部分,分别在两块 GPU 上进行训练,但只在部分层进行跨 GPU 的通信。如 Figure 2 中第 3 层会使用第 2 层的所有输出,而第 4 层只会使用同 GPU 上第 3 层的输出。具体通信方式可以使用交叉验证的方式通过实验得到。
2.4. 局部响应归一化
文章指出,虽然 ReLU 不需要对输入进行归一化来解决饱和的问题,使用局部归一化(local response normalization,LRU)仍有助于提高泛化能力。网络使用的 LRU 如下所示:
$$
b_{x, y}^i = a_{x, y}^i / \bigg( k + \alpha \sum_{j=\max(0, i-n/2)}^{\min(N-1, i+n/2)} (a_{x, y})^2 \bigg)^\beta
$$
其中 $a_{x, y}^i$ 为第 $i$ 个卷积核在位置 $(x, y)$ 的激活值,$b_{x, y}^i$ 为归一化后的值,$N$ 为该层的卷积核总数,$k, n, \alpha, \beta$ 为超参数,可以通过验证集确定,文章取值为 $k = 2, n = 5, \alpha = 10^{-4}, \beta = 0.75$。AlexNet 在第 1、2 层卷积后使用了 LRU,使用 LRU 后可以将 top-1 和 top-5 的错误率分别降低 1.4% 和 1.2%。
2.5. 重叠池化
在使用池化时,传统的方法是令池化的窗口尺寸等于步长,这样池化的窗口不会重叠。而文章使用了重叠池化(overlapping pooling),即步长小于窗口尺寸。文章观察到使用重叠池化更不容易过拟合。AlexNet 中使用了步长为 $2$ 的 $3 \times 3$ 池化,相比于步长为 $2$ 的 $2 \times 2$ 池化,top-1 和 top-5 的错误率分别降低 0.4% 和 0.3%。
3. 降低过拟合
由于网络较大,ILSVRC 的数据集仍不足以避免过拟合。文章使用了数据增强和 dropout 的方法来降低过拟合。
文章使用了两种数据增强方法。一种方法是从 $256 \times 256$ 的图像中随机裁剪 $224 \times 224$ 的小图,然后进行随机的水平翻转。在测试时,会在原图的四角和中央裁剪 5 块 $224 \times 224$ 的小图,使用这 5 张图像及其水平翻转(一共 10 张)进行预测,并对预测结果进行平均。
另一种方法是修改训练集图像 RGB 通道的强度——无论各通道强度和光照如何,要识别的物体是不变的。具体做法是计算训练集数据中各通道像素值的 PCA,然后为训练集中的图像,加上
$$
[\boldsymbol{p_1}, \boldsymbol{p_2}, \boldsymbol{p_3}] [\alpha_1\lambda_1, \alpha_2\lambda_2, \alpha_3\lambda_3]^T
$$
其中 $\boldsymbol{p_i}$ 和 $\lambda_i$ 分别为 RGB 像素值所构成 $3 \times 3$ 协方差矩阵的第 $i$ 个特征向量和特征值,$\alpha_i$ 是一个随机数,每张训练图像采样一次。这种方法可以降低 1% 的 top-1 错误率。
AlexNet 还在前两个全连接层中使用了 dropout 来降低过拟合,dropout rate 为 0.5。
4. 实验结果
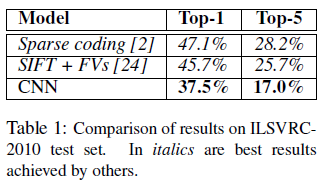
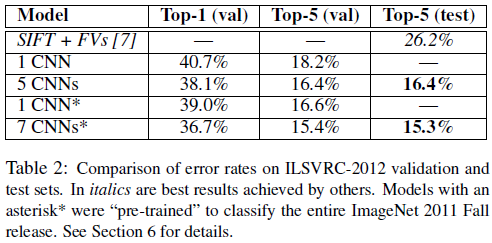
文章给出了网络在 ILSVRC-2010 和 ILSVRC-2012 的结果如 Table 1、Table 2 所示。可见 CNN 的性能要大幅优于第 2 名。
4.1. 定性分析
文章给出了网络第 1 层卷积中卷积核的可视化如 Figure 3 所示,可见这些卷积核学习的都是一些与频率和方向有关的特征。图中前 3 行是在第一个 GPU 上学习的结果,可见这些卷积核于颜色无关;后 3 行是在第二个 GPU 上学习的结果,这些卷积核与颜色有关。文章指出,这种规律不是偶然,在多次训练中都会出现,且和特定的随机权重初始化无关。

Figure 4 左图展示了 8 张图的 top-5 预测结果,网络可以识别不同位置上的对象,如第 1 张图片中左侧边缘的螨虫。top-5 中的大多数结果都比较合理,例如第 4 张花豹的其他预测结果都是猫科,又如第 7 张樱桃的 top-1 预测是斑点狗,因为图片中的樱桃难以辨认,而且斑点狗确实出现在了图片中。

文章还从测试集中选取了 5 张图片,并从训练集中找出与之距离最近的 6 张图片,如 Figure 4 右图。这里的距离指的是网络倒数第 2 层的输出长度为 4096 的向量的欧氏距离。距离越近,表示网络的高层认为两张图片越相近,尽管像素级别的距离并不一定接近,例如几张图中的大象姿态各不相同,但网络认为它们相似。通过训练自编码器对长度为 4096 的向量进行压缩,可以得到更高效的表示来计算图片的相似度,效果也会优于直接基于像素的方法。