[Reading] Mask R-CNN
Mask R-CNN (2017/3)
Contents
1. 概述
文章的主要贡献有:
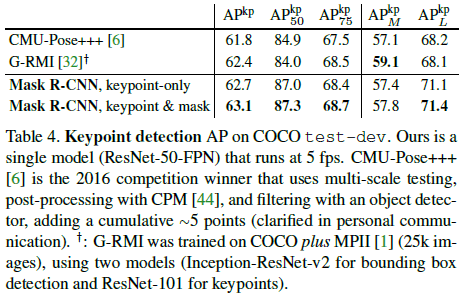
- 提出了一种实例分割的简单方法:在 Faster R-CNN 上添加了一个平行于边界框预测、用于预测目标 mask 的分支,在每个 RoI(Region of Interest)上使用 FCN(Fully Convolutional
Network)来预测 mask,如 Figure 1 所示。同时对 mask 和 类别的预测进行了解耦,提高了性能。 - 提出了一种简单且无量化的 RoIAlign 层,可以完全保留空间位置信息,以解决 RoI 池化(RoIPool)中由量化带来的输入和输出间位置无法对齐的问题。
- 通过以上方法得到的 Mask R-CNN 可以在高效地检测图像中目标的同时,为每个实例生成高质量的分割 mask,在 COCO 实例分割任务上的性能超过了当时的所有单模型方法,同时也可以用于目标检测、人体姿态估计等任务。
2. Mask R-CNN
Faster R-CNN 包含两路输出,分别用于预测目标类别和边界框偏移。Faster R-CNN 的预测过程包含两个阶段,在第一阶段会由 RPN(Region Proposal Network)生成一系列候选框,第二阶段通过 RoIPool 从候选框中提取特征向量,再使用提取的特征向量进行分类和边界框回归。
Mask R-CNN 在 Faster R-CNN 的基础上又添加了一个额外的 mask 分支,来输出目标的 mask。Mask R-CNN 也使用两阶段的方法,第一阶段与 Faster R-CNN 相同,第二阶段在预测类别和边界框偏移的同时,同时预测每个 RoI 的二值 mask。对于每个 RoI,mask 分支会为每个类别预测一个 mask,输出尺寸为 $Km^2$,其中 $K$ 为类别数量,分辨率为 $m \times m$。
在训练时,Mask R-CNN 会计算每个 RoI 的多任务损失 $L = L_{cls} + L_{box} + L_{mask}$,其中 $L_{cls}$ 和 $L_{box}$ 分别为分类损失和边界框损失,定义与 Fast R-CNN 相同;由于 mask 是二值的,可以将对 mask 的预测看成是对其中每个像素的二分类,在每个像素上使用 sigmoid 进行预测,由此可将 $L_{mask}$ 定义为 RoI 上的平均二元交叉熵。对于属于类别 $k$ 的 RoI,只计算第 $k$ 个 mask 的损失。
文章指出,在如 FCN 之类的语义分割方法中,会使用 softmax 对像素进行分类,并使用多项式交叉熵,这样不同类别的 mask 间会产生竞争。而上述 $L_{mask}$ 通过使用逐像素的 sigmoid 和二元损失,不会引入类别间的竞争,将 mask 和类别的预测进行了解耦。网络会根据分类分支预测的类别,选择对应的 mask 作为输出。文章通过实验发现这是获得更好的实例分割效果的关键。
2.1. mask 的表示方法
Mask R-CNN 利用卷积计算像素到像素的对应关系,使用 FCN 为每个 RoI 预测 $m \times m$ 的 mask。这就要求 RoI 特征图要能够对齐到像素,保留与像素之间的在空间上的对应关系。
2.2. RoIAlign
Faster R-CNN 通过 RoIPool 对各种尺寸的 RoI 进行特征提取,得到固定 $k \times k$ 尺寸(如 $7 \times 7$)的特征图。这一过程涉及两次量化:
- RoIPool 会首先对 RoI 的坐标进行量化。RoI 来自 RPN 的预测,其坐标是浮点数,要将其离散化到整数的坐标值;
- RoIPool 还会对 RoI 的区域进行量化(分桶)。为了在不同尺寸的 RoI 上提取 $k \times k$ 的固定尺寸输出,要将 RoI 平均划分为 $k \times k$ 个单元(桶),在每个单元内部进行池化。
举例来说,对于连续坐标 $x$,首先会量化为 $[x / 16]$,其中 $16$ 为特征图步长,$[\cdot]$ 表示圆整;然后会被量化到 $7 \times 7$ 网格的一个单元中。这些量化操作会使得 RoIPool 的输入和输出无法在空间上对齐,虽然对在 RoI 上的分类影响不大,但会对像素级的 mask 产生很大影响。
文章提出了 RoIAlign 来解决这一问题。RoIAlign 移除了量化,在每个 RoI 桶中均匀采样 4 个位置,使用双线性插值计算每个位置上的特征值,如 Figure 3 所示。RoIAlign 带来了大幅的性能提升。

2.3. 网络架构
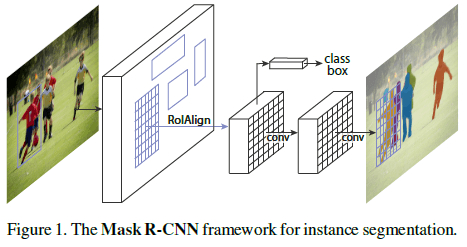
文章尝试了不同的 backbone 架构,如 Figure 4 所示。对于 ResNet,使用第 4 个 stage 的最后一个卷积层输出的特征 C4 作为 backbone 的输出,从 RoI 提取的 $7 \times 7 \times 1024$ 特征图再经过 ResNet 的第 5 个 stage(res5),用于各个 head 的预测。在预测 mask 的 head 上,使用两个卷积层输出 $14 \times 14 \times 80$ 的 mask。使用 FPN(Feature Pyramid Network) 作为 backbone 时,会在金字塔的各个层上提取 RoI 特征,FPN 中已经包含了 res5,这样各个 head 的计算就更加高效。实验发现使用 ResNet-FPN 作为 backbone 对准确率和速度都有提升。
2.4. 实现细节
2.4.1. 训练
训练时,如果 RoI 与标注框有至少 0.5 的 IoU,则认为是正例,否则认为是负例。$L_{mask}$ 只定义在正例 RoI 上,mask 的预测目标是 RoI 与对应标注 mask 的交集。
每张图像首先经过缩放,使得最小边长为 800 像素。构造小批量时,文章使用了 Fast R-CNN 的方式,每个 GPU 的每个小批量包含两张图片(文章使用了 8 个 GPU),每张图片上采样 $N$ 个 RoI(backbone 使用 C4 时取 $N = 64$,使用 FPN 时取 $N = 512$),并保持正负例比例为 $1:3$。
RPN 使用了 5 种尺度和 3 种长宽比的锚点框。虽然 RPN 和 Mask R-CNN 可以共享 backbone,但文章为了便于比较,将二者分开训练。
2.4.2. 推断
推断时,RPN 首先会生成一系列候选区域(backbone 使用 C4 时生成 300 个,使用 FPN 时生成 1000 个),然后由边界框预测分支对在每个候选区域进行预测,得到一系列检测框;经过 NMS 后,选择分数最高的 100 个检测框,由 mask 预测分支进行预测,为每个 RoI 预测 $K$ 个 mask,并选择第 $k$ 个 mask 作为输出,$k$ 是分类分支对类别的预测。所选的 mask 是一个分辨率为 $m \times m$ 的浮点矩阵,将其缩放到 RoI 的尺寸后,使用 0.5 的门限进行二值化。
注意推断时并没有并行地使用三个分支进行预测,而是先对检测框进行了过滤,仅保留高质量的 RoI,可以在加快推断速度的同时提高准确率。
3. 实验结果
3.1. 实例分割
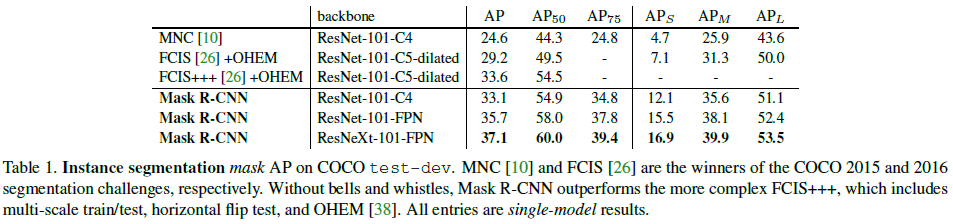
Mask R-CNN 在实例分割任务上的性能如 Table 1 所示,可见 3 种 Mask R-CNN 的性能都超过了之前的 SOTA 模型。
3.1. 消融实验
3.1.1. 架构
Table 2a 展示了在 Mask R-CNN 中使用不同 backbone 的效果,可见更深的网络(ResNet-101)和更先进的结构(RPN、ResNeXt)会带来更好的性能。文章同时指出并不是所有的框架都能自动从更深和更先进的网络中自动受益。

3.1.2. 多项(multinomial)vs 独立 mask
Mask R-CNN 将 mask 和类别的预测进行了解耦,通过逐像素的 sigmoid 和二元交叉熵,为每个类别预测 mask,类别间没有竞争。而如 FCN 之类的方法,使用逐像素的 softmax 和多项式损失,将 mask 和类别的预测耦合起来。文章比较了这两种方法的性能,如 Table 2b 所示,可见使用 sigmoid 的 AP 要大幅高于 softmax。
3.1.3. 类别特定/类别不可知 mask
前述 Mask R-CNN 会在每个 RoI 上为每个类别预测一个 mask,每个 mask 对应特定类别,mask AP 为 30.3。文章同时发现,预测类别不可知的 mask,即为每个 RoI 只预测一个 mask,可以达到相近的性能,mask AP 为 29.7。
3.1.4. RoIAlign
Table 2c 比较了 RoIAlign 的性能,可见相比 RoIPool 和 RoIWarp,RoIAlign 具有最佳的性能,且对使用最大池化还是平均池化不敏感。此外 RoIWarp 中也使用了双线性插值,但其性能与 RoIPool 接近,而差于 RoIAlign,说明对齐非常重要。
文章还尝试将步长从 16 像素增大到 32 像素,效果如 Table 2d 所示。与 Table 2c 相比,可见步长增加后, RoIPool 性能发生下降,且低于 RoIAlign;而 RoIAlign 在步长增加后性能反而从 30.3 提升到 30.9,说明 RoIAlign 在很大程度上解决了使用大步长特征来进行检测和分割的挑战。
此外 RoIAlign 与 FPN 一起使用时,可以提升 1.5 的 mask AP 和 0.5 的 box AP。RoIAlign 在关键点检测任务上也会带来很大提升,如 Table 6 所示。
3.1.5. mask 分支
Table 2e 比较了在 mask 分支使用不同结构进行预测的效果,可见使用 FCN 的 AP 要高于 MLP。
3.2. 边框检测
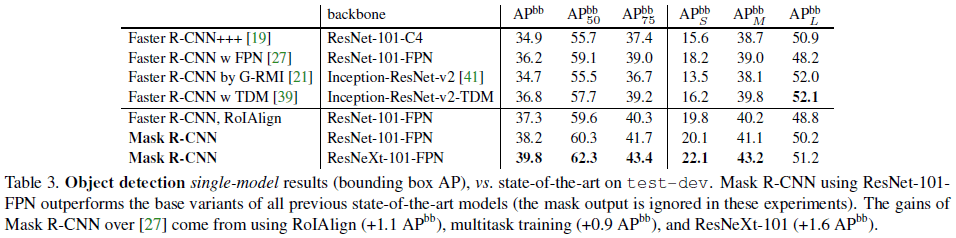
Table 3 展示了 Mask R-CNN 在边框检测上的性能,可见 Mask R-CNN 的性能也超过了之前的 SOTA 方法。Table 3 中的 “Faster R-CNN, RoIAlign” 为移除了 mask 分支的 Mask R-CNN,可见其性能超过了之前的 Faster R-CNN,但略差于 Mask R-CNN,Mask R-CNN 在这里的优势来自多任务训练。
3.3. 人体姿态估计
Table 4 展示了 Mask R-CNN 在边框检测上的性能,以 $62.7 AP^{\mathrm{kp}}$ 的性能超过了之前的 SOTA 方法,且更快、更简单。