[Reading] YOLO9000: Better, Faster, Stronger
YOLO9000: Better, Faster, Stronger (2016/12)
Contents
1. 概述
文章的主要贡献有:
- 使用一系列方法对 YOLO 进行了改进,提出了名为 YOLOv2 的模型,在获得高 mAP 的同时速度也非常快,并能适应不同分辨率的图像,可以在速度和准确率之间进行取舍。
- 提出了一种联合目标检测和图像分类的训练的方法,通过同时使用 COCO 检测数据集和 ImageNet 分类数据集进行训练,得到的 YOLO9000 可以实时检测超过 9000 种不同的物体,甚至可以检测没有检测标注数据的物体。
文章指出,目标检测数据集通常较小,使得目标检测任务也局限于少数几个类别。相比之下,用于分类的数据集有大量的图片数据和类别。由于标注检测数据的成本较高,不太可能出现大规模的检测数据集,于是文章提出了一种联合训练的算法,使用 WordTree 整合不同来源的数据集,可以在目标检测任务的训练过程中同时使用检测和分类数据集:通过检测数据集学习精确定位,通过分类数据集提高词汇量和鲁棒性,缩小了检测和识别两个任务间的差距。
2. Better
文章使用一系列方法针对 YOLO 定位不准和召回低的问题进行了改善。各种优化对 YOLOv2 的提升如 Table 2 所示。

2.1 Batch Normalization
通过在 YOLO 的所有卷积层后添加 BN,可以带来超过 2% 的 mAP 提升。同时也移除了 dropout,移除后并不会发生过拟合。
2.2. 高分辨率分类器
YOLO 先使用 $224 \times 224$ 尺寸的图像训练分类网络,然后将分辨率提升至 $448 \times 448$ 用于检测任务,使得分类器必须重新适应更高的分辨率。YOLOv2 在训练分类网络时,直接使用 $448 \times 448$ 分辨率的 ImageNet 图像训练训练 10 个 epoch,使得分类网络可以更好地适应高分辨率的检测输入,由此带来接近 4% 的 mAP 提升。
2.3. 带锚点框的卷积
YOLO 直接在特征图上使用全连接层来预测边界框的坐标,而 Faster R-CNN 使用了一系列先验的锚点框,通过预测相对于锚点框的偏移来得到边界框。相比于直接预测边界框坐标,预测相对锚点框的偏移要更加简单。文章移除了 YOLO 中的全连接层,使用锚点框来预测边界框。
引入锚点框后,要为每个锚点框进行类别预测和 objectness 预测。objectness 表示标注框和预测框的 IOU,类别预测表示在有物体的条件下物体类别的条件概率。
使用锚点框会小幅降低准确率,但可以提升召回率。使用前 YOLO 有 69.5 的 mAP 和 81% 的召回率;使用后则有 69.2 的 mAP 和 88% 的召回率。召回率的提升说明模型还有进一步提升的空间。
2.4. 维度聚类
使用锚点框的一个问题是如何选择锚点框的尺寸。锚点框的尺寸是手动选择的,如果能选择更好的先验锚点框,网络就越容易给出准确的预测。为此文章尝试通过在训练集上对标注框的尺寸进行 k 均值聚类,来找到更好的先验锚点框。
文章指出,如果在聚类时使用欧氏距离,小边界框会产生更多误差。聚类实际目标是找到具有较高 IOU 的先验框,与框的尺寸无关,于是文章使用了如下的距离指标
$$
d(\mathrm{box}, \mathrm{centroid}) = 1 – \mathrm{IOU}(\mathrm{box}, \mathrm{centroid})
$$
文章尝试了不同的 $k$,结果如 Figure 2 所示,最终选择了 $k = 5$。
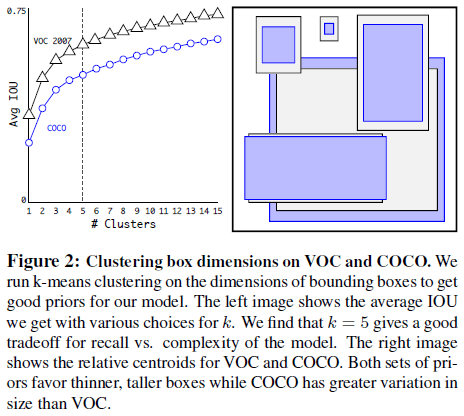
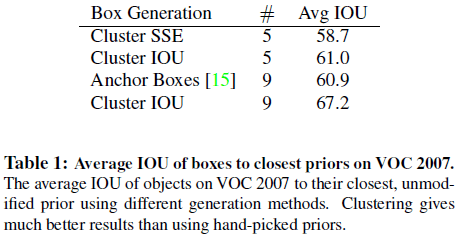
Table 1 进一步比较了通过不同策略得到的先验锚点框的性能,可见在相同的 $k$ 下,通过聚类得到的锚点框具有更高的平均 IOU,表明使用聚类得到的锚点框可以让模型有更好的起点,学习预测准确的边界框也更容易。
2.5. 直接位置预测
使用锚点框的另一个问题是迭代早期对边界框位置 $(x, y)$ 的预测不稳定。在同样使用锚点框的 RPN(region proposal networks)中,网络预测的边界框位置是相对于锚点框的偏移量 $(t_x, t_y)$
$$
x = (t_x * w_a) – x_a \\
y = (t_y * h_a) – y_a
$$
$t_x$ 和 $t_y$ 的取值范围较大,如 $t_x = 1$ 表示将边界框向右移动 $w_a$(锚点框宽度),$t_x = -1$ 表示将边界框向左移动 $w_a$。对模型随机初始化后,需要较长时间才能获得合理的偏移量预测。
在对边界框的位置进行预测时,文章改而预测边界框中心坐标相对于网格单元的偏移量。物体中心所在的网格单元负责预测该物体,边界框中心相对于网格单元的偏移量就限制在 0 到 1 之间。网络在每个网格单元预测 5 个边界框,每个边界框有 5 个预测值 $t_x, t_y, t_w, t_h, t_o$。假设网格单元本身相对图片左上角的偏移量为 $c_x, c_y$,锚点框宽高为 $p_w$ 和 $p_h$,如 Figure 3 所示,则预测的边界框为
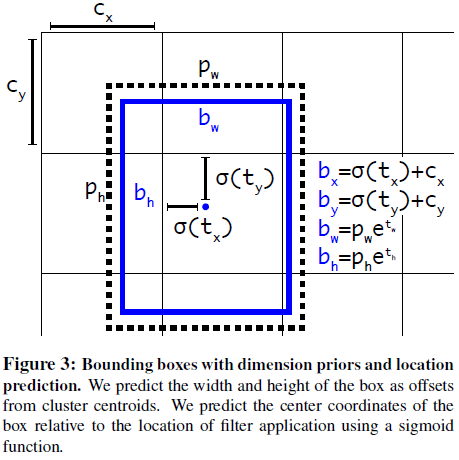
$$
\begin{aligned}
b_x &= \sigma(t_x) + c_x \\
b_y &= \sigma(t_y) + c_y \\
b_w &= p_w e^{t_w} \\
b_h &= p_h e^{t_h} \\
Pr(\mathrm{object}) * IOU(b, \mathrm{object}) &= \sigma(t_o)
\end{aligned}
$$
注意上式中边界框的坐标 $(b_x, b_y)$ 和网格单元的位置 $(c_x, c_y)$ 有关,而和锚点框位置无关。使用这种方法限制了位置预测的范围($0$ 到 $1$),更容易进行学习,网络也更稳定。使用维度聚类和直接预测边界框中心位置的方法,YOLO 的性能比不使用锚点框提高了 5%。
2.6. 细粒度特征
YOLOv2 在 $13 \times 13$ 的特征图上进行预测,为了提高对小物体的检测能力,文章添加了一个 passthrough 层来将高分辨率特征和低分辨率特征结合起来,来增加更细粒度的特征。高分辨率特征图中的相邻特征被放入不同的通道,使其宽高减小而通道数增加,获得与低分辨率特征相匹配的尺寸,然后和低分辨率特征拼接起来。如 $26 \times 26 \times 512$ 的特征图先被转换为 $13 \times 13 \times 2048$,然后再和最后的 $13 \times 13$ 的特征图拼接。由此可以得到 1% 的性能提升。
2.7. 多尺度训练
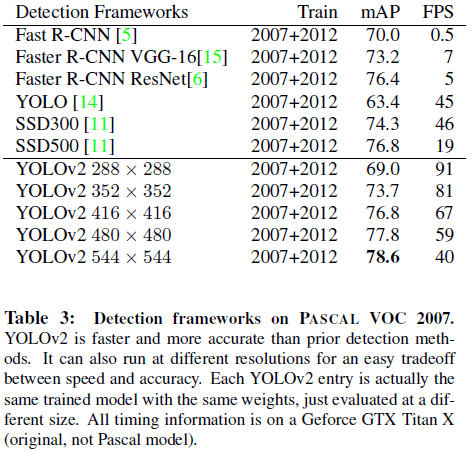
YOLO 使用 $448 \times 448$ 的固定输入,文章希望 YOLOv2 能够在不同尺寸的图像上稳定运行,在训练中使用了不同尺寸的图像。文章以 32 的步长对图像进行一系列下采样,得到一组图像尺寸 $\{320, 352, \dots, 608\}$,其中最低 $320 \times 320$,最高 $608 \times 608$。在训练中每 10 批就重新随机选择图像尺寸。由此得到的网络可以不同分辨率的图像上进行预测,在小分辨率图像上速度更快,在高分辨率图像上精度更高,可以在二者之间进行取舍,如 Tabel 3、Figure 4 所示。
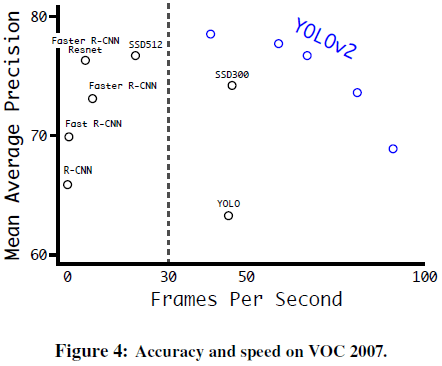
2.8. 实验结果
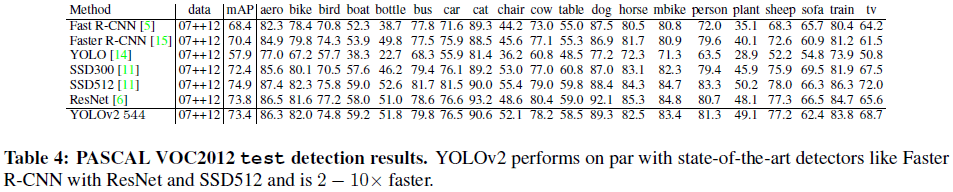
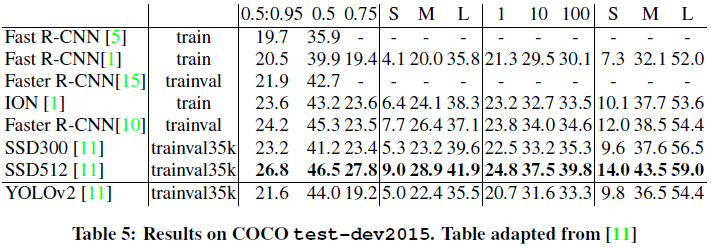
文章给出了 YOLOv2 在 VOC 2012 和 COCO 上的性能如 Table 4、Table 5所示。
3. Faster
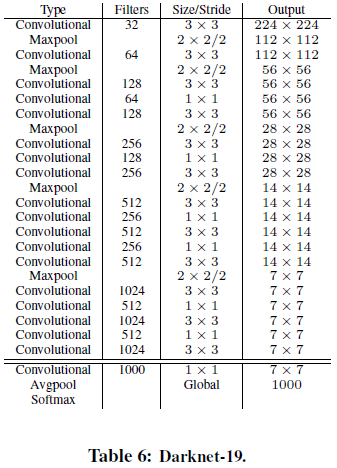
为了进一步提高检测速度,文章提出了名为 Darknet-19 的分类网络作为 YOLOv2 的基础。Darknet-19 遵循了 VGG 的设计思路,主要使用 $3 \times 3$ 卷积,每次池化后让通道数翻倍。网络也借鉴了 NIN(Network in
Network)的设计,在网络最后使用全局池化进行分类,使用 $1 \times 1$ 卷积来在 $3 \times 3$ 卷积间压缩特征图。同还时使用了 batch normalization。最终得到的 Darknet-19 网络结构如 Table 6 所示。
文章先使用 ImageNet 数据集训练网络进行分类,初始训练时使用 $224 \times 224$ 的分辨率,然后再微调到 $448 \times 448$。之后移除最后一个卷积层,加上 3 个 $3 \times 3$ 卷积层,最后再加上一个 $1 \times 1$ 卷积输出检测结果。对于 VOC 数据集,网络预测 5 个边界框,每个边界框包含 5 个坐标和 20 个类别,输出长度为 125。此外,网络还在最后一个 $3 \times 3 \times 512$ 卷积层和倒数第二个卷积层间增加了 passthrough 层来引入细粒度特征。
4. Stronger
文章提出了一种联合分类数据和检测数据进行训练的方法,从检测数据中学习检测相关任务,并利用分类数据集扩展网络能够检测的类别数量。在训练时,对于检测数据会按完整的代价函数进行反向传播,对于分类数据则只会反向传播分类相关的部分。
分类数据集中类别的标签粒度更细,如 ImageNet 中有超过 100 种不同的狗,如诺福克梗犬(Norfolk terrier)、约克夏梗犬(Yorkshire terrier);而检测数据集中通常只有粗粒度的标签,如“狗”。这两种不同粒度的标签并不是互斥的,不能把两个数据集简单地合并在一起。
为此文章提出了一种多标签的模型,使用 WordNet 为 ImageNet 的类别标签构造了一颗树,即视觉概念的分层模型,称为 WordTree。进行预测时,会在树的每个节点预测在目标属于该节点类别的情况下,目标属于各个下义词的条件概率,如在梗犬(terrier)节点,预测
$$
Pr(\mathrm{Norfolk terrier}|\mathrm{terrier}) \\
Pr(\mathrm{Yorkshire terrier}|\mathrm{terrier}) \\
Pr(\mathrm{Bedlington terrier}|\mathrm{terrier}) \\
\dots
$$
要计算特定节点的绝对概率,只需沿路径向上找到根节点,将路径上节点的概率相乘
$$
\begin{aligned}
Pr(\mathrm{Norfolk terrier}) = & Pr(\mathrm{Norfolk terrier}|\mathrm{terrier}) \\
& * Pr(\mathrm{terrier}|\mathrm{hunting dog}) \\
& * \dots * \\
& * Pr(\mathrm{mammal}|\mathrm{anima}) \\
& * Pr(\mathrm{anima}|\mathrm{physical\;object})
\end{aligned}
$$
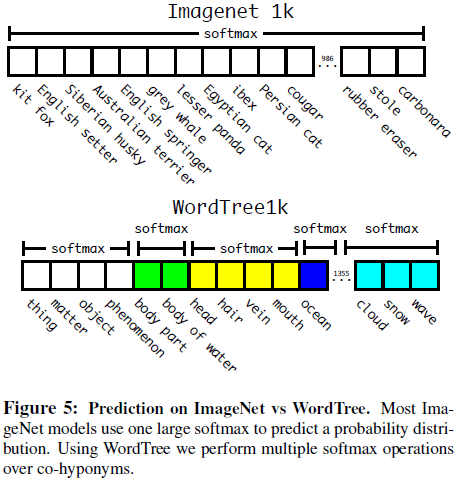
对于分类任务,认为图像中一定有物体,即 $Pr(\mathrm{physical\;object}) = 1$。文章使用 ImageNet 的 1000 个类别构造 WordTree,期间加入了一些中间节点,得到的树有 1369 个标签。训练时对于每个样本,在树中找到该样本的标签节点,并将从该节点到树根节点之间的所有标签都作为该样本的真实标签,如 Norfolk terrier 的样本会被同时标记为 dog 和 mammal。预测时,对所有属于同一概念的下义词计算 softmax,如 Figure 5 所示。
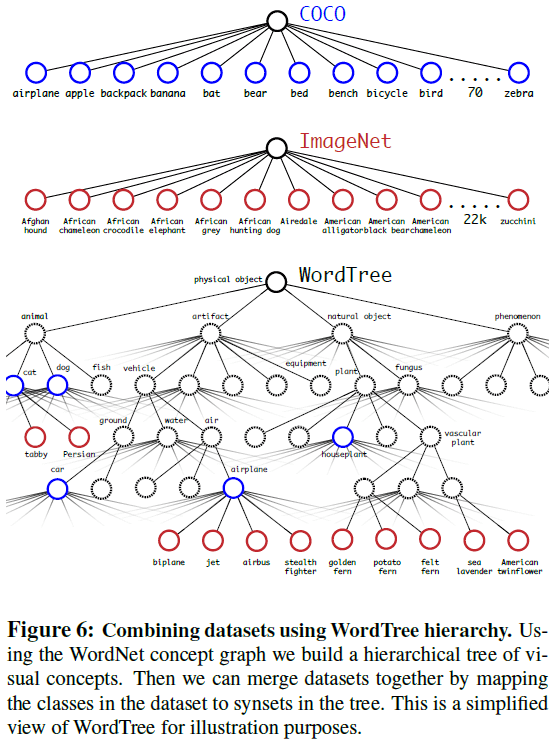
通过 WordTree 可以将数据集组合起来,如 Figure 6 所示。文章使用 COCO 检测数据集和 ImageNet 前 9000 个类别的数据,构造了包含 9418 个类别的 WordTree。由于 COCO 的数据量要比 ImageNet 少得多,文章对 COCO 数据集进行了过采样, 使得 ImageNet 的数据量比 COCO 大 4 倍。使用这些数据进行训练时,对于检测数据可以按正常方式进行反向传播,对于分类数据则只将误差传播到当前和更高级的标签上,例如某图片的标签为 dog,则对其的分类误差不会传播到下层的如 German Shepherd 的标签上,因为 dog 这个标签没有信息表明狗的具体品种。使用这些数据训练得到了 YOLO9000。
文章在 ImageNet 检测任务上对 YOLO9000 进行了测试,测试数据中只有 44 个类别出现在 COCO 检测数据集中,对检测任务中的绝大部分测试图像,YOLO9000 只见过分类数据,但仍达到了 19.7 的整体 mAP,在从未见过检测数据的 156 个类别上的 mAP 达到了 16.0。YOLO9000 不仅能检测超过 9000 个类别的对象,还能保证检测的实时性。