[Reading] MnasNet: Platform-Aware Neural Architecture Search for Mobile
MnasNet: Platform-Aware Neural Architecture Search for Mobile (2018/7)
Contents
1. 概述
文章的主要贡献有:
- 提出了一种移动端神经架构搜索(mobile neural architecture search,MNAS)的方法,同时将模型的准确率和在真实设备上的延迟作为搜索的目标,以获得二者之间的平衡。
- 提出了一种分层搜索空间(factorized hierarchical search space),来提高各层结构的多样性,来生成适合移动端等资源受限场景下使用的 CNN 网络。
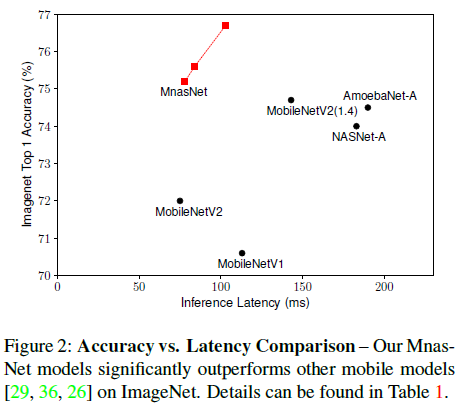
- 基于以上方法,构造了 MnasNet 网络架构。在图像识别和目标检测任务中,MnasNet 相较其他移动端模型,在保持低延迟的同时,获得了更好的性能,如 Figure 2 所示。
针对如移动端等计算能力有限的场景,需要对模型的准确率和延迟进行合理的取舍,这增加了人工进行网络设计的难度。因此文章希望通过自动搜索的方法来找到合适的网络架构,通过将准确率和延迟同时作为搜索的目标,来对准确率和延迟进行取舍。
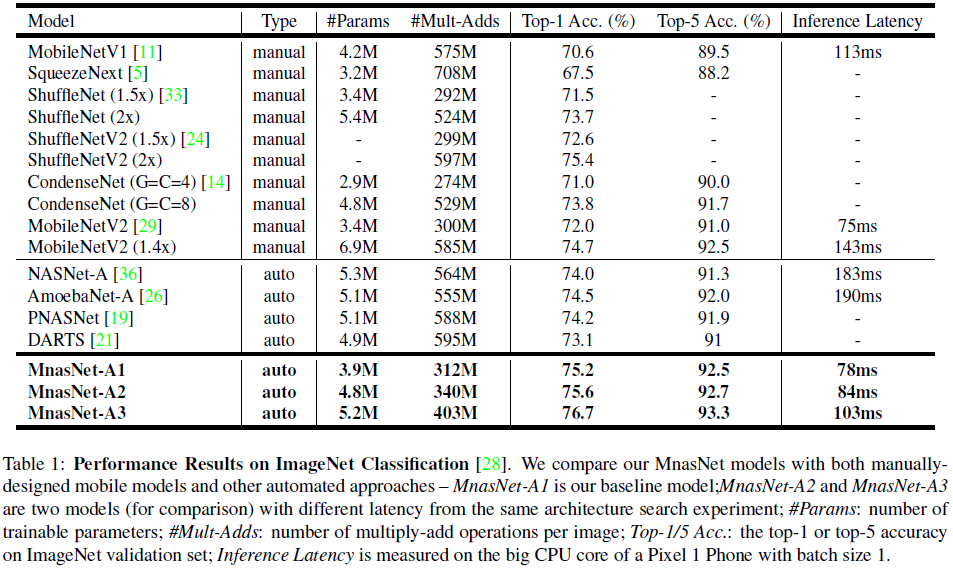
前人的工作中,通常使用 FLOPS 来评价模型延迟,然而这是不准确的。例如 MobileNet 和 NASNet 具有相近的 FLOPS,分别为 575M 和 564M,然而二者的延迟则有很大差别,分别为 113ms 和 183ms。因此文章引入了平台感知的真实世界延迟信息(platform-aware real-world latency information),使用真实设备来测试模型的延迟,贴合模型的实际使用情况。
在之前的神经架构搜索(NAS)方法中,为了简化搜索过程,通常只是搜索几种 cell 的架构,然后通过重复堆叠得到完整网络,网络的层结构比较单一。为了提高计算效率,有必要增加层结构的多样性,例如 CNN 在前后阶段的计算量不同,需要使用不同的结构来有效地利用计算资源。因此文章提出了分层搜索空间,使搜索得到的各层可以有不同的结构,平衡灵活性和搜索空间大小。具体来说,文章将 CNN 网络分成一系列预定义的 block,然后对每个 block 进行搜索。每个 block 由一系列重复的层结构组成,只需在一个较小的子搜索空间中对层结构和重复次数进行搜索。这样每个 block 都可以有不同的结构,同时搜索空间又远小于直接对整个网络架构进行搜索。
2. 搜索方法
2.1. 搜索框架
文章使用的搜索框架如 Figure 1 所示,其中 Controller 对模型进行采样,得到的模型由 Trainer 训练后,一方面在验证集上计算准确率(accuracy),一方面在真实设备上计算延迟(latency),二者共同构成收益(reward),据此更新控制器参数。

2.2. 搜索目标
给定模型 $m$,记模型在目标任务上的准确率为 $ACC(m)$,在目标移动平台上的推理延迟为 $LAT(m)$,目标延迟为 $T$。为了在搜索时同时考虑模型准确率和延迟,常见做法是将 $T$ 作为硬约束,并最大化准确率,即
$$
\begin{aligned}
\underset{m}{\mathrm{maximize}} \; & ACC(m) \\
\text{subject to} \; & LAT(m) \leq T
\end{aligned} \tag{1}
$$
文章指出,这种方法只是最大化了准确率这个单一指标,无法得到帕累托最优(Pareto optimal),即在不增加延迟的情况下达到最大准确率,或在不降低准确率的情况下达到最低延迟。
文章使用了准确率和延迟的加权乘积作为优化目标
$$
\underset{m}{\mathrm{maximize}} \; ACC(m) \times \bigg[ \frac{LAT(m)}{T} \bigg]^w \tag{2}
$$
其中 $w$ 为权重因子,定义为
$$
w = \begin{cases}
\alpha & \text{if } LAT(m) \leq T \\
\beta & \text{otherwise} \end{cases}
$$
如果设置 $\alpha = 0, \beta = -1$,则当 $LAT(m) \leq T$ 时,优化目标将只包含 $ACC(m)$;当 $LAT(m) > T$,将进行惩罚,如 Figure 3 上图所示。
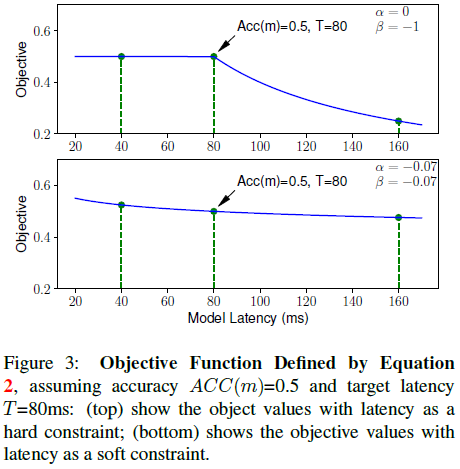
选择 $\alpha$ 和 $\beta$ 的一个经验准则是,保证不同准确率-延迟取舍的帕累托最优解具有相近的收益。文章观察到延迟加倍会给准确率带来大约 5% 的相对提升,假设模型 M1 延迟为 $l$,准确率为 $a$,收益为 $Reward(M1) = a \cdot (l / T)^\beta$,则对于延迟为 $2l$ 的模型 M2,其准确率为 $a \cdot (1 + 5\%)$,收益为 $Reward(M2) = a \cdot (1 + 5\%) \cdot (2l / T)^\beta$。这两个模型应具有相同的收益,即 $Reward(M2) \approx Reward(M1)$,可以解得 $\beta \approx -0.07$,因此文章使用 $\alpha = \beta = -0.07$,如 Figure 3 下图所示。
2.3. 分层搜索空间
为了提高层结构的多样性,文章将 CNN 网络分成一系列预定义的 block,逐渐降低分辨率并增加过滤器数量,通过对各个 block 进行搜索,使得不同的 block 可以具有不同的层架构,如 Figure 4 所示。
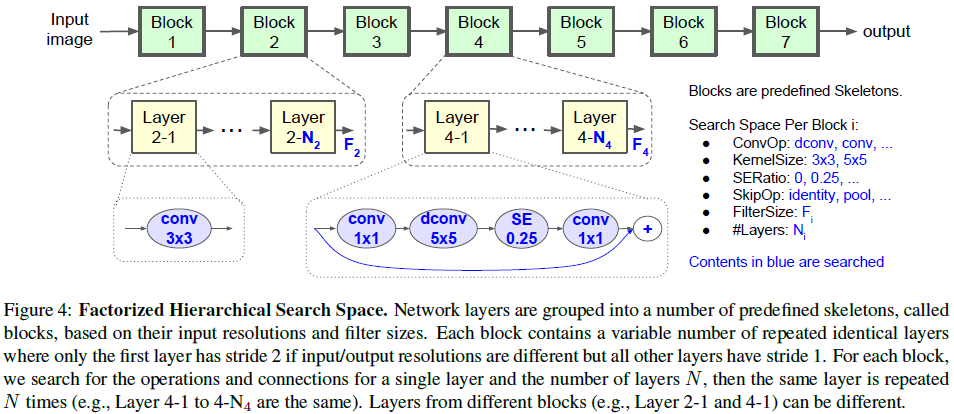
其中每个 block 的子搜索空间包括

Figure 4 中的 ConvOp、KernelSize、SERatio、SkipOp 和 FilterSize $F_i$ 决定了层的架构,$N_i$ 控制该层在 block 中重复的次数。例如 Figure 4 中的 Layer 4-1 表示选择了一个 inverted bottleneck 和一个残差连接,该层在 Block 4 中重复了 $N_4$ 次。
分层搜索空间的一大优势是平衡了层的多样性和搜索空间的大小。假设网络有 $B$ 个 block,每个 block 平均有 $N$ 层,子搜索空间为 $S$,对于分层搜索空间,每个 block 只搜索一种层结构,总搜索空间大小为 $S^B$。如果逐层进行搜索,则搜索空间大小为 $S^{B * N}$。典型地,对于 $S = 432, B=5, N = 3$,分层搜索空间的大小为 $10^{13}$,逐层搜索的搜索空间的大小为 $10^{39}$。
2.4. 搜索算法
文章延续了 NASNet 的思路,将学习生成神经网络架构看成是一个强化学习问题,将控制器基于参数 $\theta$ 输出的网络结构参数看成是动作 $a_{1:T}$,目标是最大化期望收益
$$
J = E_{P(a_{1:T};\theta)}[R(m)] \tag{5}
$$
其中 $m$ 是由动作 $a_{1:T}$ 决定的模型,$R(m)$ 是式 $(2)$ 定义的目标值。
文章也使用了 RNN 作为控制器,控制器首先根据其参数 $\theta$ 采样一批模型,对每个模型 $m$,训练后获得准确率 $ACC(m)$,然后在真实设备上执行推断获得延迟 $LAT(m)$,计算得到收益 $R(m)$,据此更新控制器参数 $\theta$ 以最大化式 $(5)$ 定义期望收益。
3. 实验结果
由于直接在如 ImageNet 和 COCO 这些大数据集上进行搜索的计算量太大,之前的 NAS 通常使用如 CIFAR-10 的小数据集。但文章指出,在引入延迟之后,小数据集不再适用,因此选择通过在 ImageNet 上训练少量(5个)epoch 来进行搜索,在 64 个 TPU 上,每次搜索耗时 4.5 天。控制器总共采样了 8K 个模型,选择了最好的 15 个迁移到 ImageNet,选择了最好的 1 个迁移到 COCO。
网络在 ImageNet 上的性能如 Table 1 所示,搜索的目标延迟与 MobileNetV2 类似,设置 $T = 75 ms$,$\alpha = \beta = -0.07$,最终选择了具有不同延迟-准确率取舍的三个最佳模型参与对比。可见参数最少的 MnasNet-A1 就已经达到了 SOTA 性能,相较 MobileNetV2 (1.4x),准确率高 0.5%,速度快 1.8 倍。相较同样是搜索得到的 NASNet-A,MnasNet-A1 准确率高 1.2%,速度快 2.3 倍。
MnasNet 中使用了 SE(squeeze-and-excitation),为了排除 SE 的影响,文章比较了不带 SE 的 MnasNet 的效果如 Table 2 所示。可见即便排除了 SE,MnasNet 的性能依旧优于 MobileNetV2。

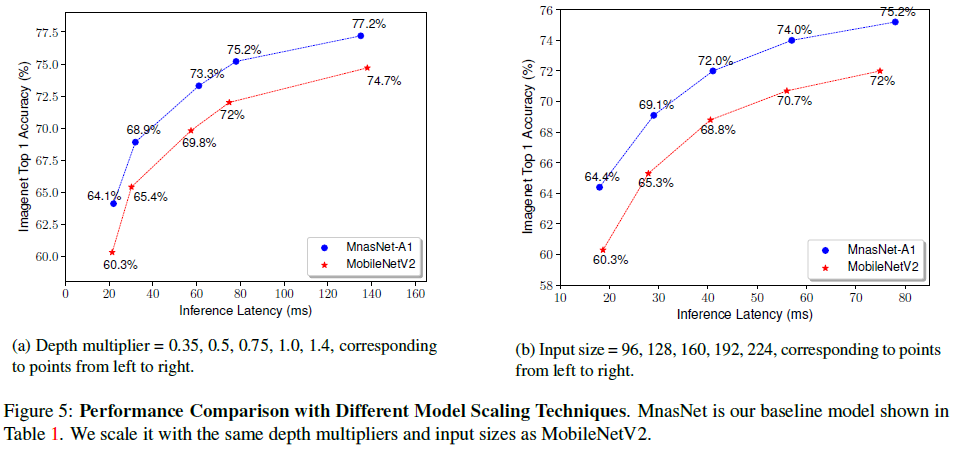
实际场景中,经常要通过增加深度或通道数的方法,对模型进行缩放,来获得不同准确率和延迟的模型。文章比较了 MnasNet 的缩放性能,如 Table 5 所示,可见 MnasNet 在不同缩放尺度上都稳定优于 MobileNetV2。
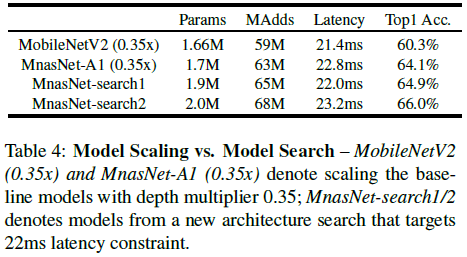
此外文章还专门为不同延迟单独进行了搜索,并比较了搜索和缩放两种方法的性能,如 Table 4 所示。可见与缩放模型相比,专门搜索的模型具有更好的性能。
文章将 Table 2 中的 MnasNet 用于 SSDLite,测试了在 COCO 目标检测任务上的性能,如 Table 3 所示。可见 MnasNet-A1 + SSDLite 的性能显著优于 MobileNetV2 + SSDLite,与 SSD300 相当,而其参数数量和乘加数量远少于 SSD300。

4. 讨论
4.1. 软/硬约束
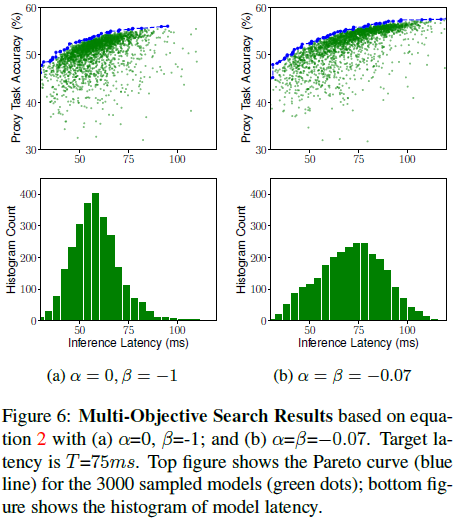
文章测试了在式 $(2)$ 中使用不同 $\alpha$ 和 $\beta$ 的效果,如 Figure 6 所示。如果令 $\alpha = 0, \beta = -1$,则延迟的要求变成了硬约束(延迟要求满足时不会产生代价,不满足时产生代价),控制器会更偏向生成低延迟的模型;如果令 $\alpha = \beta = -0.07$,则延迟的要求是软约束,控制器搜索延迟的范围会更大,可以得到更多的帕累托最优解。
4.2. 搜索空间和收益
文章中使用的多目标收益和分层搜索空间都有助于获得更好的模型。为了区分二者的贡献,文章分别测试了单/多目标收益和 NASNet(Cell-based)/ MnasNet 搜索空间的组合,如 Table 5 所示。可见对于相同的搜索空间,相比于单目标收益,多目标收益可以在损失准确率的情况下,获得更快的模型;同样对于多目标收益,MnasNet 搜索空间可以找到更快和更准确率更高的模型。

4.3. 层的多样性
分层搜索空间有助于提高层结构的多样性。Figure 7(a) 展示了 MnasNet 架构,可见它确实具有更丰富的层结构。其中 MBConv 表示 mobile inverted bottleneck conv,DWConv 表示 depthwise conv。
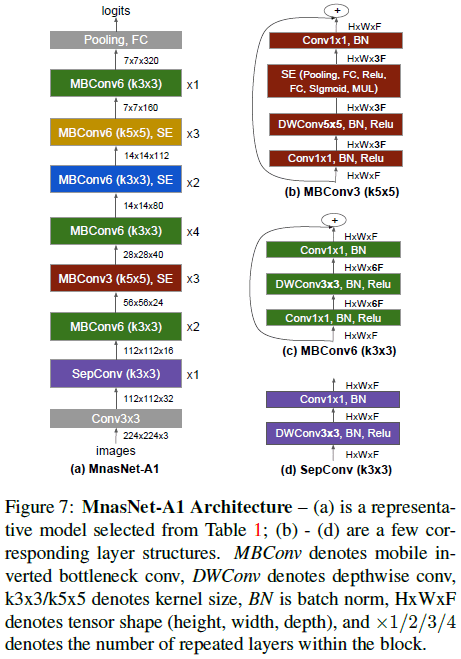
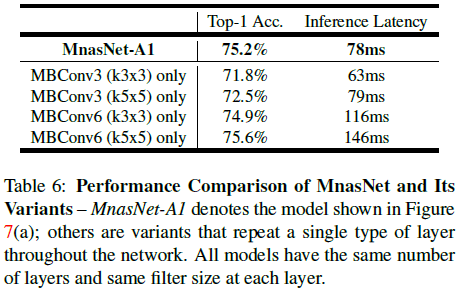
Table 6 比较了 MnasNet 和只重复一种层结构的效果,可见 MnasNet 可以更好地平衡准确率和延迟。