[Reading] Learning Transferable Architectures for Scalable Image Recognition
Learning Transferable Architectures for Scalable Image Recognition (2017/7)
1. 概述
文章的主要贡献有:
- 提出了一种直接在感兴趣的数据集上学习网络架构的方法,学到的架构可以灵活地缩放至不同的计算和参数量,来适应不同场景的需要,同时还具有超过人工设计模型的性能。
- 设计了易于迁移的 NASNet 搜索空间,将架构的复杂度和网络的深度进行解耦。由此就可以先在较小的数据集上通过搜索找到高效的卷积 cell 架构,再迁移到大数据集的图像识别和物体检测任务上。
- 在 CIFAR-10 数据集上找到了高效的卷积层结构,并用其构造了 NASNet 网络架构,在 CIFAR-10 和 ImageNet 上的性能都超过了人工设计的模型,还可以用于目标检测等其他任务。
- 展示了可以对学得的架构进行缩放。通过缩小 NASNet,降低了计算量,性能也超过了已有的面向移动端和嵌入式平台的模型。
文章使用的神经网络架构搜索(Neural Architecture Search,NAS)方法来自 Neural Architecture Search with Reinforcement Learning 一文,通过强化学习的方式来搜索网络架构,如 Figure 1 所示,使用 RNN 作为控制器对网络架构进行采样,然后对得到的子网络(child network)进行训练和测试,根据验证集准确率更新控制器参数。
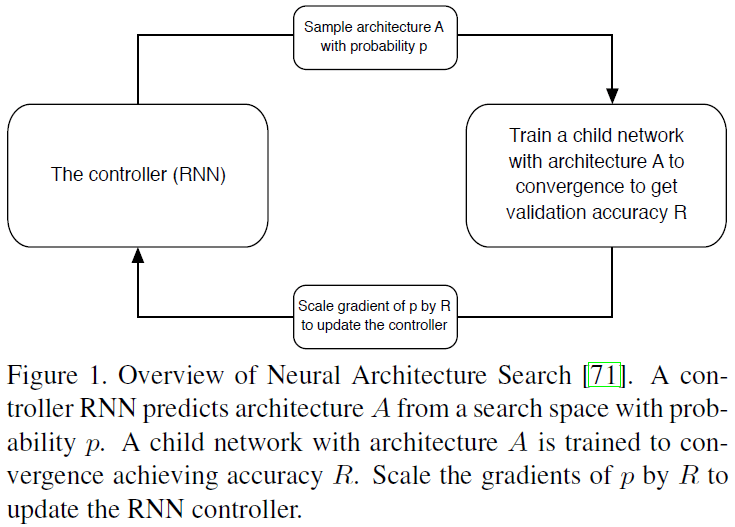
NAS 的整个流程需要大量的计算,不适合直接应用在大数据集上,因此文章选择先在较小的 CIFAR-10 数据集上进行搜索,然后再迁移到较大的 ImageNet 数据集上。为了便于迁移,文章提出的 NASNet 搜索空间将架构复杂度与网络深度、输入尺寸进行了解耦,搜索的目标是最佳的卷积 cell 结构,而不是整个网络,这样一方面提高了搜索速度,另一方面也更容易泛化到其他问题上。网络的整体架构是人工预先定义的,使用学到的 cell 堆叠而成。
2. 搜索方法
2.1. 网络架构
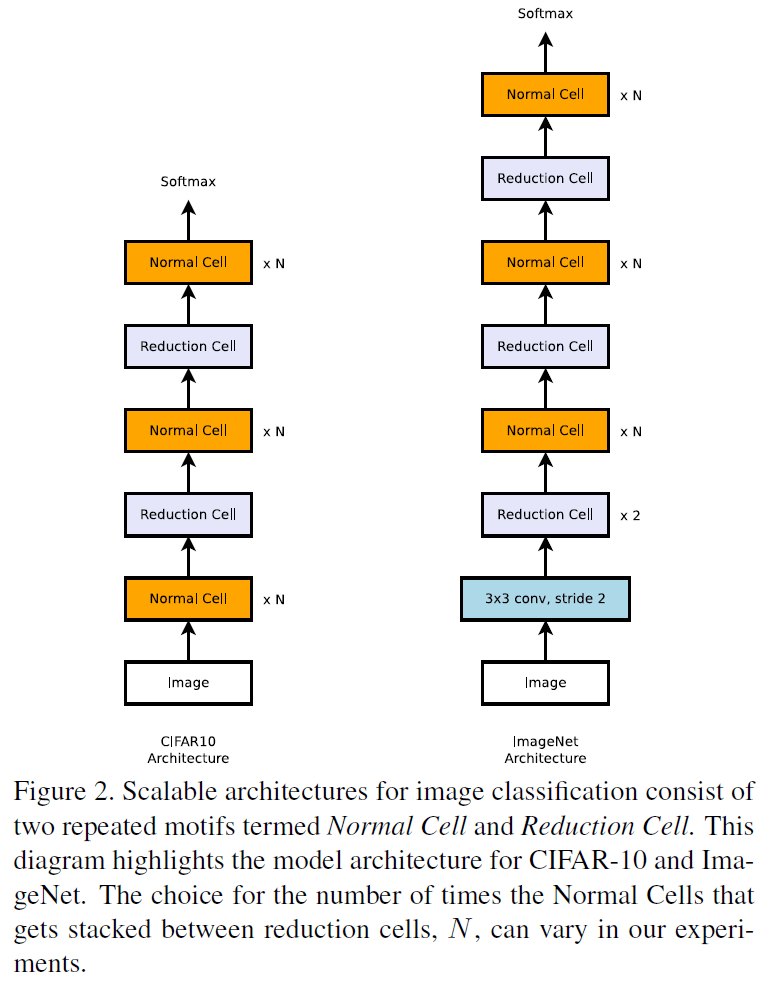
如前所述,文章通过 NAS 搜索的是最佳的卷积 cell 结构。为了构建可缩放的、适用于不同图像分辨率的架构,文章定义了两种 cell:
- Normal Cell:输出的特征图尺寸和输入相同
- Reduction Cell:输出的特征图长和宽减半(通过设置 cell 中第一个操作的步长为 2 来实现)
使用以上两种 cell,文章构造了用于 CIFAR-10 和 ImageNet 的网络架构如 Figure 2 所示。由此得到的用于 CIFAR-10 或 ImageNet 的网络,其架构都是固定的,区别只在于通过搜索得到的 cell 的结构。
2.2. 卷积 cell 搜索
给定两个初始的隐藏状态,使用 RNN 作为控制器递归地预测 cell 的架构,如 Figure 3 所示。对每个 cell 的预测分为 $B$ 个 block,对每个 block 的预测分为 5 个步骤,由 5 个不同的 softmax 分类器输出选择:
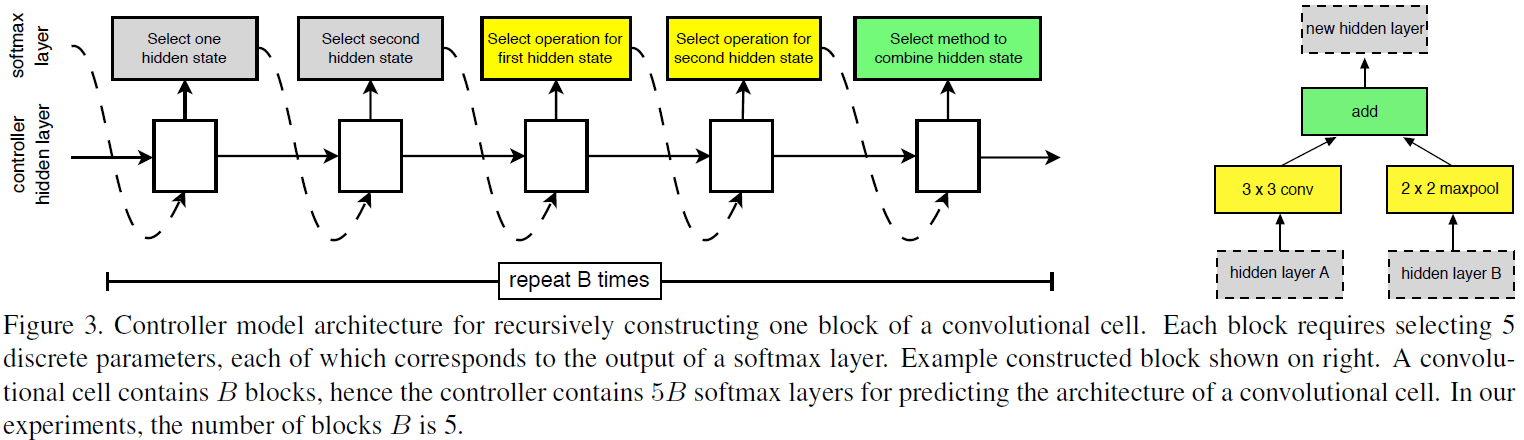
- 从 $h_1, h_{i-1}$ 或之前 block 的隐藏状态中选择一个隐藏状态。
- 使用步骤 1 的方法,选择第二个隐藏状态。
- 选择应用于步骤 1 隐藏状态的操作。
- 选择应用于步骤 2 隐藏状态的操作。
- 选择组合步骤 3、4 的方法,产生一个新的隐藏单元。
以上步骤重复 $B$ 次,就得到一个包含 $B$ 个 block 的卷积 cell。实验中选择 $B = 5$ 就可以得到很好的效果。
在步骤 3 中,候选的操作包括以下几种:

在步骤 5 中,候选的组合两个隐藏层的方法包括以下两种:
- 逐元素相加
- 在过滤器维度上拼接
在生成的卷积 cell 中,所有未使用的隐藏状态,都按深度拼接,作为 cell 的输出。
为了生成前述的 Normal 和 Reduction 两种 cell,可以让控制器预测 $2 \times 5B$ 次,前 $5B$ 次作为 Normal Cell,后 $5B$ 次作为 Reduction Cell。
3. 实验结果
3.1. 性能比较
文章使用 CIFAR-10 数据集,使用 Proximal Policy Optimization(PPO)方法在 500 个 GPU 上训练了 4 天,得到了一系列卷积 cell,其中性能最好的 Normal Cell 和 Reduction Cell 如 Figure 4 所示。可见每个 cell 中都包含 5 个 block,最后将各个 block 的结果拼接起来作为 cell 的输出。

得到卷积 cell 结构之后,为了确定网络架构,还需要决定 cell 重复的次数 $N$,以及初始卷积 cell 的过滤器数量。确定初始过滤器数量后,在之后的层中,如果步长为 2,则将过滤器数量加倍。文章使用 4@64 的形式表示 cell 重复 $4$ 次、倒数第二层有 $64$ 个过滤器的网络架构。最后通过全局平均池化、全连接层和 softmax 进行分类(实现)。使用搜索的结果,文章给出了 NASNet-A、NASNet-B、NASNet-C 三个模型。
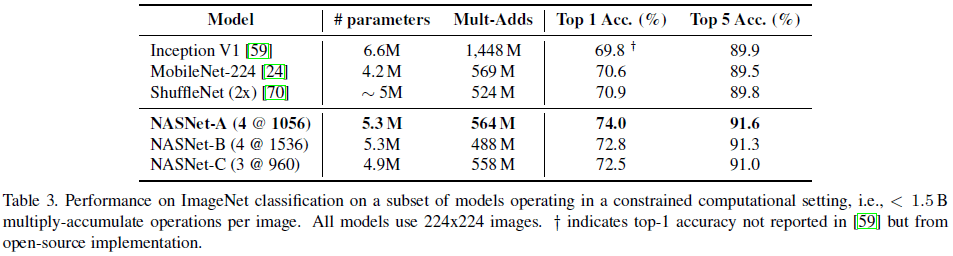
NASNet 在 CIFAR-10 上的性能如 Table 1 所示,其中 NASNet-A (7@2304) + cutout 达到了 2.40% 的错误率,略优于之前最佳的 2.56%。
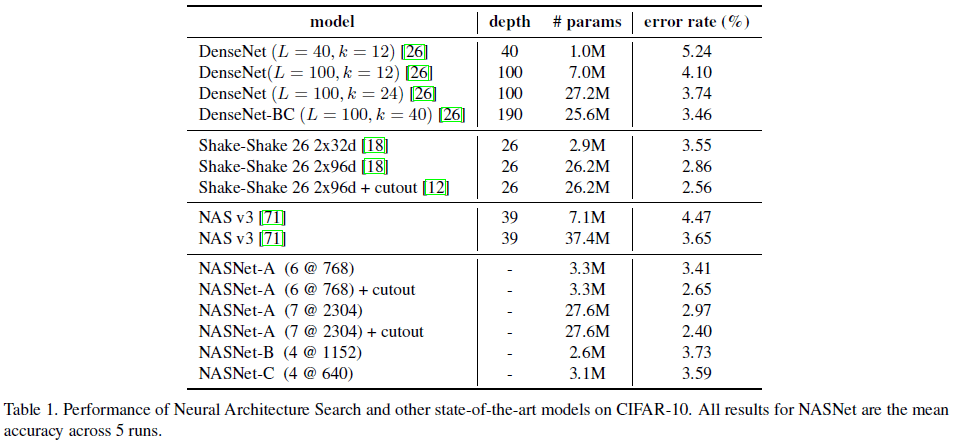
文章将在 CIFAR-10 上搜索得到的架构,迁移到 ImageNet 图像识别上,并对其性能进行了对比,如 Table 2 所示。可见在 CIFAR-10 上搜索得到的卷积 cell 可以很好地泛化到 ImageNet 图像识别任务上,仅靠单模型就可以达到最高 82.7% 的 top-1 准确率,与之前最佳性能的 SENet 打平,但 NASNet 的参数数量和计算量要远小于 SENet。
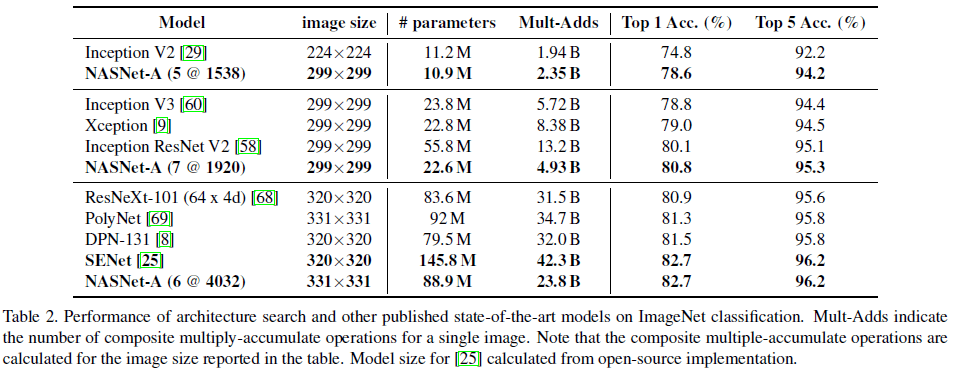
由 Figure 5 可见,NASNet 系列模型构成的包络覆盖了一系列手工设计的模型。
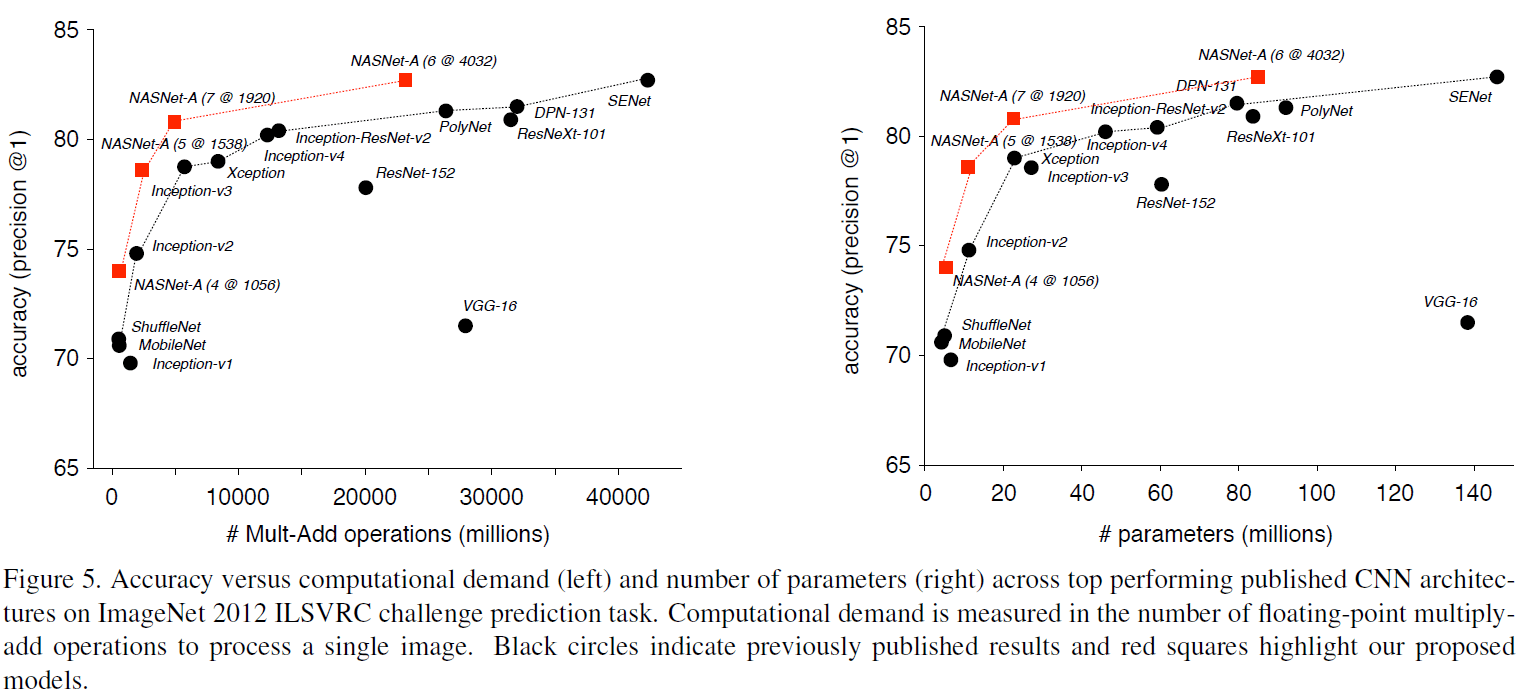
文章还比较了在模型在资源受限场景下的性能,如 Table 3 所示。可见 NASNet 的性能超过了之前的模型,而计算量与之前模型大致相同,说明搜索得到卷积 cell 适用于不同尺寸的模型,在计算量几乎降低两个数量级的情况下,依然可以达到 SOTA 性能。
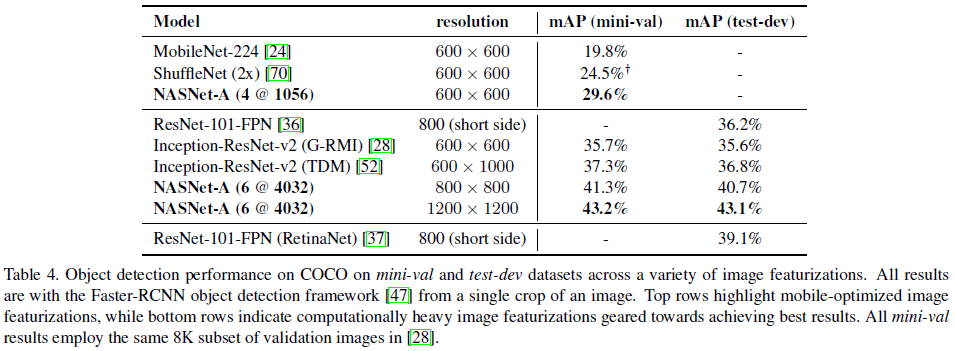
文章将 ImageNet 预训练的 NASNet-A 用于 Faster-RCNN 物体检测,性能如 Table 4 所示。NASNet-A (4 @ 1056) 的 mAP 达到 29.6%,超过了其他移动端模型。NASNet-A (6 @ 4032) 的 mAP 达到了最高的 43.1%,超过了之前的最佳性能(39.1%),
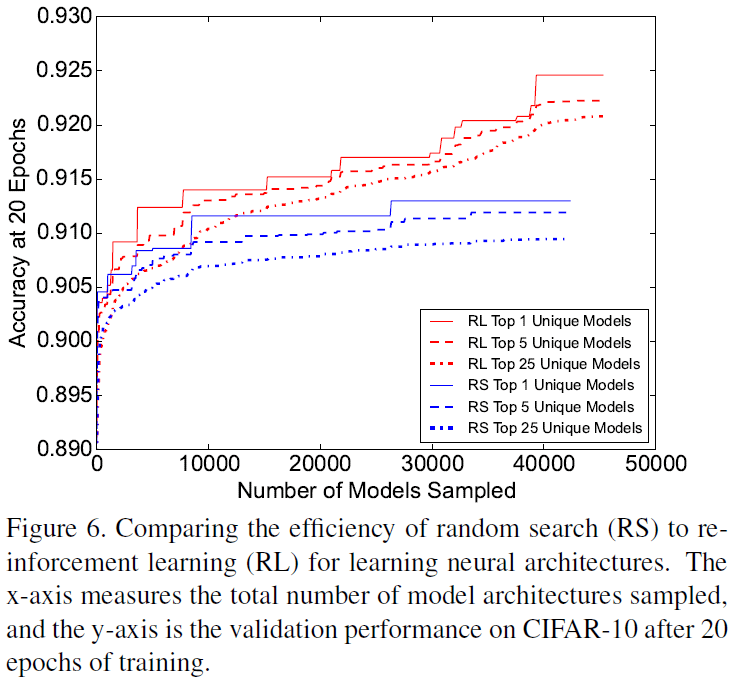
3.2. 搜索方式比较
为了研究通过强化学习进行 NAS 的效率,文章对比了随机搜索(RS)和强化学习(RL)进行架构采样的性能,如 Figure 6 所示。可见强化学习采样的最佳模型性能要显著高于随机搜索,前者在 CIFAR-10 上的准确率要比后者高 1%。此外强化学习采样的一系列模型的性能,也都高于随机搜索。这说明虽然随机搜索是一种可行的搜索策略,但强化学习能够找到更好的架构。