[Reading] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (2017/7)
1. 概述
文章使用 pointwise 分组卷积(group convolution)来降低卷积的计算量,并使用 channel shuffle 来保证模型的表达能力,构建了一种非常高效的 CNN 架构,称为 ShuffleNet,在相同计算复杂度下,其性能超过了 MobileNet。
更深和更大的网络在获得更高性能的同时,也会消耗大量的计算量。文章同期的 Xception 和 ResNeXt 虽然通过高效的深度可分离卷积和分组卷积降低计算量,但其中的 $1 \times 1$ 卷积(pointwise 卷积)占用了大部分的计算量,例如 ResNeXt 只在 $3 \times 3$ 卷积上使用分组卷积,单个残差单元中 pointwise 卷积占据了 93.4% 的乘加数。为了进一步降低计算量,需要减少通道数量,而这又会损害性能。
为了在保证通道数量的前提下降低计算量,一种方法是让通道间的连接变得稀疏,如在 $1 \times 1$ 卷积层上也使用分组卷积。分组卷积中某个组的输出只和对应的输入组有关,如 Figure 1(a) 所示,多个分组卷积叠加,会降低信息在通道分组间的传递,影响模型的表达能力。
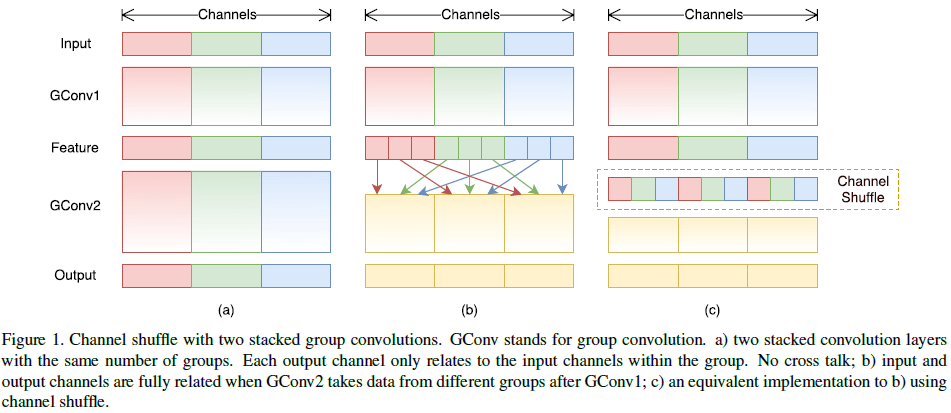
为了解决这个问题,可以让每个分组卷积获得前一层不同组的数据作为输入,即将组内的各通道再细分为若干子组,使用不同分组下的子分组作为下一层的分组的输入,如 Figure 1(b) 所示。这可以通过如 Figure 1(c) 所示的 channel shuffle 操作实现,假设卷积层有 $g$ 个分组,每个分组有 $n$ 个通道,则将该层输出变形为 $(g, n)$ 的形状,然后进行转置,再压平回原形状,作为下一层输入。
2. 网络架构
2.1. ShuffleNet 单元
文章构造的 ShuffleNet 单元借鉴了 ResNet 的 bottleneck residual block。首先在 $3 \times 3$ 卷积上使用了计算量更少的 depthwise 卷积(Figure 2(a));然后将第一个 $1 \times 1$ 卷积替换为 pointwise 分组卷积,后接 channel shuffle;最后通过 $1 \times 1$ 卷积来匹配 shortcut path 的通道数(Figure 2(b))。如果 depthwise 卷积使用了步长,则在 shortcut path 上添加一个平均池化,并将最后的逐元素相加替换为通道拼接,在缩小特征图空间尺寸的同时增加通道数量(Figure 2(c))。
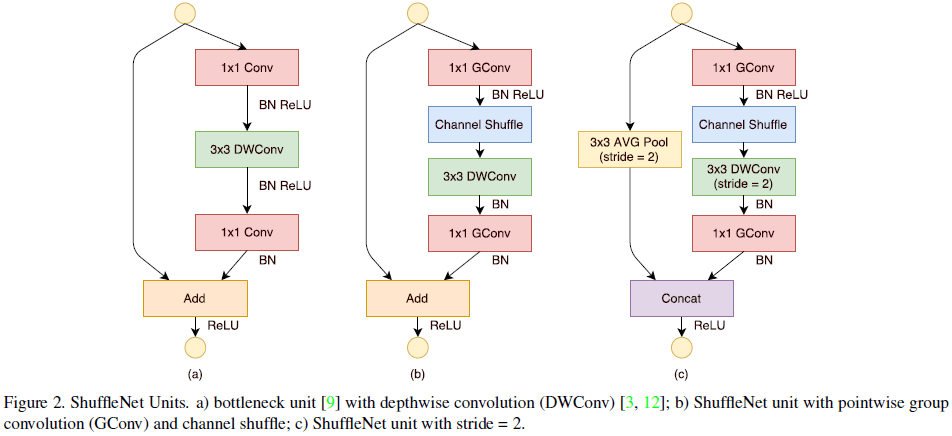
ShuffleNet 单元结构简单,假设输入尺寸为 $c \times h \times w$,bottleneck 通道数为 $m$,分组卷积的分组数为 $g$,则计算量为 $hwcm/g + 3^2 hwm + hwcm/g = hw(2cm/g + 9m)$ FLOPs。相比之下,ResNet 和 ResNeXt 对应结构的计算量分别为 $hw(2cm + 9m^2)$ 和 $hw(2cm + 9m^2/g)$ FLOPs,都远大于 ShuffleNet 单元的计算量。对用相同的计算资源,ShuffleNet 可以有更多的通道数,即可以使用更宽的特征图。
文章提到,虽然 depthwise 卷积的计算并不复杂,但却很难在移动端等低功耗设备上有效实现,其计算效率比反而低于密集操作。因此 ShuffleNet 单元只在 bottleneck 中使用了 depthwise 卷积,来尽量避免额外的开销。
2.2. ShuffleNet 架构
文章给出了 ShuffleNet 的架构如 Table 1 所示,包括 ShuffleNet 单元叠加构成的 3 个 stage,其中 $g$ 为分组数量,控制了 pointwise 卷积的稀疏度。

3. 实验结果
文章主要在 ImageNet 2012 分类数据集上对模型进行了各种测试。
为了验证 pointwise 分组卷积的效果,文章在大致保持计算复杂度的条件下尝试了不同的 $g$ 的取值,同时通过缩放因子 $s$ 对通道数量进行缩放,结果如 Table 2 所示。注意当 $g = 1$ 时,相当于没有分组,此时 ShuffleNet 单元变成类似 Xception 的结构。

从 Table 2 可见,$g > 1$ 的网络性能都要优于没有使用 pointwise 分组卷积($g = 1$)的网络。分组数量越多,相同计算量下可以使用的通道数就越多,理论上模型的性能越强,但部分模型的性能提升随 $g$ 的增加而逐渐饱和,ShuffleNet 0.5X 在 g = 8 时出现劣化。分组数量越多,单个过滤器输入的通道数量就越少,反而会影响模型的表达能力。但对于 ShuffleNet 0.25X 这种较小的模型,模型性能始终随通道数的增加而增加,说明更宽的特征图对小模型更有益处。
为了验证通道 channel shuffle 的效果,文章比较了不使用 shuffle 的模型的性能,结果如 Tabel 3 所示。可见 channel shuffle 可以提升模型性能,且对较大分组数量($g = 8$)的网络提升更大。
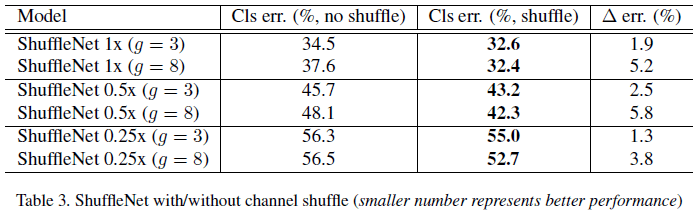
Table 4 比较了 ShuffleNet 单元和其他结构的性能,可见 ShuffleNet 单元在不同计算量下的性能都优于其他结构。

Table 5 对 ShuffleNet 和 MobileNet 进行了比较,可见 ShuffleNet 在不同计算量下的性能都优于 MobileNet。其中 ShuffleNet 2X (with SE[13], g = 3) 使用了 Squeeze-and-Excitation。
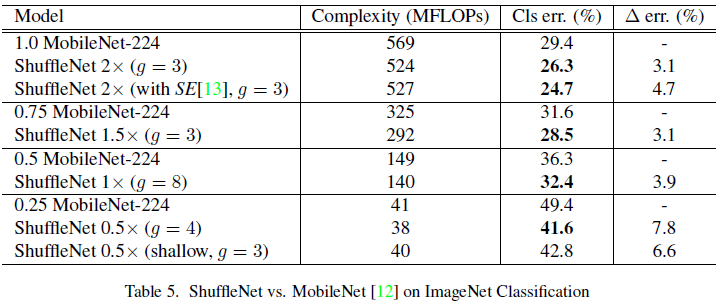
Table 6 对比了 ShuffleNet 和其他常见网络,可见相似性能下,ShuffleNet 的计算量大幅少于其他网络,

文章还验证了 ShuffleNet 的泛化能力,在 Faster-RCNN 中使用 ShuffleNet 进行目标检测,结果如 Table 7 所示。 其中 ShuffleNet 2X(524 MFLOPs)和 MobileNet(569 MFLOPs)复杂度接近,但前者性能大幅超越了后者。

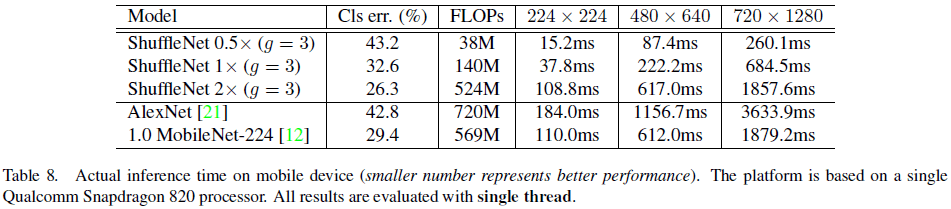
文章最后测试了 ShuffleNet 在移动端(ARM)的推断速度,如 Table 8 所示。文章指出,使用较大的 $g$ 虽然具有更好的性能,但具体实现却不够高效,因此文章使用了 $g = 3$ 来在平衡准确率和推断时间。