[Reading] Neural Architecture Search with Reinforcement Learning
Neural Architecture Search with Reinforcement Learning (2016/11)
Contents
1. 概述
文章的主要贡献有:
- 提出了一种自动化搜索神经网络架构的方法,称为神经网络架构搜索(Neural Architecture Search,NAS)。这种方法使用循环神经网络(RNN)生成可变长度网络描述,以此来构建神经网络模型。其中的 RNN 作为控制器,通过强化学习的方式训练,来最大化所生成模型在验证集上准确率的期望。
- 通过 NAS 分别生成了用于图像识别的卷积神经网络(CNN),以及用于语言建模的 RNN 单元,都获得了很好的效果。证明通过 NAS 可以得到高性能的网络架构,且其性能可以泛化到其他任务。
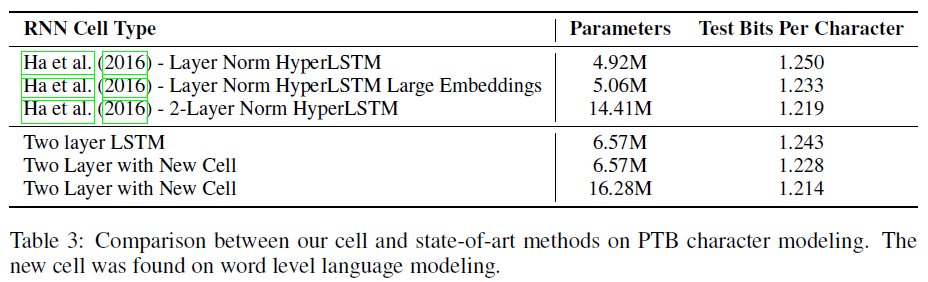
文章给出 NAS 的过程如 Figure 1 所示。
神经网络的架构可以用一个可变长度的字符串来描述,因此也就可以使用一个循环网络(控制器)来生成。生成的网络称为子网络(child network),在真实数据上训练后,使用验证集上的准确率作为奖励信号,由此计算策略梯度,来更新控制器。在下个迭代,控制器就会有更高的概率输出具有更高准确率的网络架构。
2. 搜索方法
2.1. RNN 控制器
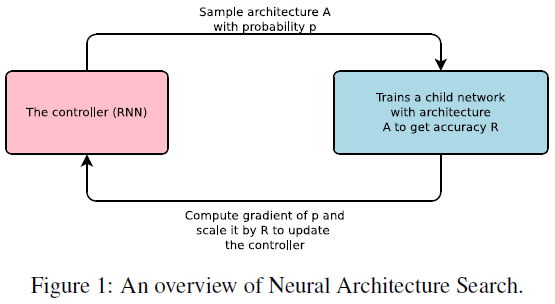
文章使用 RNN 作为控制器,来生成网络架构相关的一系列参数,Figure 2 展示了生成 CNN 的情况。控制器逐层生成网络的各参数,当总层数到达一定数量时停止生成,得到一个网络。然后训练这个生成的网络直到收敛,记录在留出的验证集上的准确率,据此更新 RNN 控制器的参数 $\theta_c$,以最大化生成网络的准确率的期望。此外生成的网络层数也会随着 RNN 控制器的训练而逐渐增加。
2.2. 训练方法
文章将学习生成神经网络架构看成是一个强化学习的问题,将控制器输出的网络结构参数看成是动作 $a_{1:T}$,生成的网络经训练收敛后,在验证集上的准确率作为回报 $R$,训练控制器来最大化期望回报
$$
J(\theta_c) = E_{P(a_{1:T} ; \theta_c)}[R]
$$
$R$ 不可微,需要使用策略梯度来迭代更新 $\theta_c$,文章使用了 REINFORCE 算法
$$
\nabla_{\theta_c} J(\theta_c) = \sum_{t=1}^T E_{P(a_{1:T}; \theta_c)} \big[\nabla_{\theta_c} \log P(a_t|a_{(t-1):1}; \theta_c) R \big]
$$
上式近似为
$$
\frac{1}{m} \sum_{k=1}^m \sum_{t=1}^T \nabla_{\theta_c} \log P(a_t|a_{(t-1):1}; \theta_c) R_k
$$
其中 $m$ 是控制器在一个 batch 中生成的不同架构的数量,$T$ 是控制器生成一个架构所需预测的超参数数量,$R_k$ 是生成的第 $k$ 个网络的验证集准确率。为了降低方差,文章使用历史架构准确率的指数滑动平均作为 baseline $b$,即
$$
\frac{1}{m} \sum_{k=1}^m \sum_{t=1}^T \nabla_{\theta_c} \log P(a_t|a_{(t-1):1}; \theta_c) (R_k – b)
$$
2.3. 增加架构复杂度
Figure 2 中所示的结构只能生成逐层堆叠的架构,为了让控制器能够预测类似 ResNet 中的 skip connection,在每层之后添加了一个额外的 anchor point,如 Figure 4 所示。
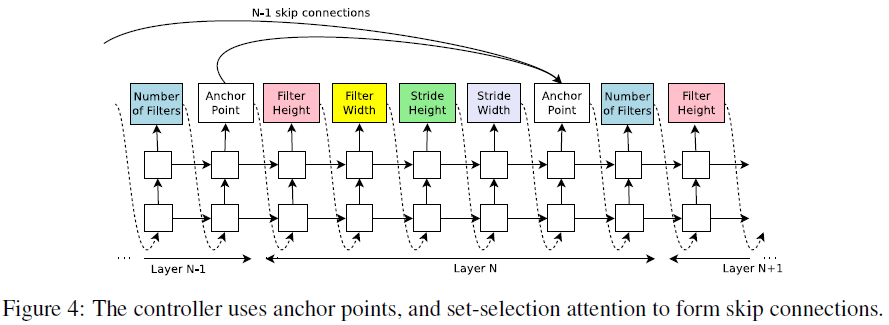
第 $N$ 层的 anchor point 其中包含了 $N – 1$ 个 sigmoid,来预测是否将之前的某层直接连接过来,即
$$
\mathrm{P}(\text{Layer } j \text{ is an input to layer } i) = \mathrm{sigmoid} \big( v^T \tanh(W_{prev} * h_j + W_{curr} * h_i) \big)
$$
其中 $h_j$ 为第 $j$ 层 anchor point 的隐藏状态,$W_{prev}$、$W_{curr}$、$v$ 为可训练的参数。
建立了 skip connection 之后,某一层可能会有多个输入,此时将多个输入在通道维度上拼接起来。但拼接两层的输出具有相同的尺寸,如果尺寸不同,文章使用补零的方法,先对较小的尺寸进行补充,再进行拼接。
如果网络中的某一层没有与之前的层有任何连接,则这一层作为输入层。在最后一层,将之前所有没有被拼接的输出拼接起来,作为最后分类器的输入。
上面的例子只是预测了卷积层,通过在控制器中添加额外的步骤来预测层类型,可以引入池化、BatchNorm 等不同类型的层。此外还可以加入学习率等其他超参数的预测。
2.4. 生成 recurrent cell 架构
文章给出了生成循环网络中 cell 结构的方法。对于循环网络中的 cell,搜索算法需要生成一个形如 $h_t = f(x_t, h_{t-1})$ 的函数 $f$,如 $h_t = \tanh( W_1 * x_t + W_2 * h_{t-1})$。文章将此类函数的结构看成一棵树,树的叶子节点的输入为 $x_t$ 和 $h_{t-1}$,树的节点代表一个二元函数,根节点输出为 $h_t$,如 Figure 5 左图所示。在 LSTM 中每个 cell 还有额外的输入 $c_{t-1}$ 和额外的输出 $c_{t}$,可以在控制器最后加入两个额外的步骤来预测 $c_{t-1}$ 和 $c_{t}$ 和树中的哪个节点相连,如 Figure 5 中图所示。
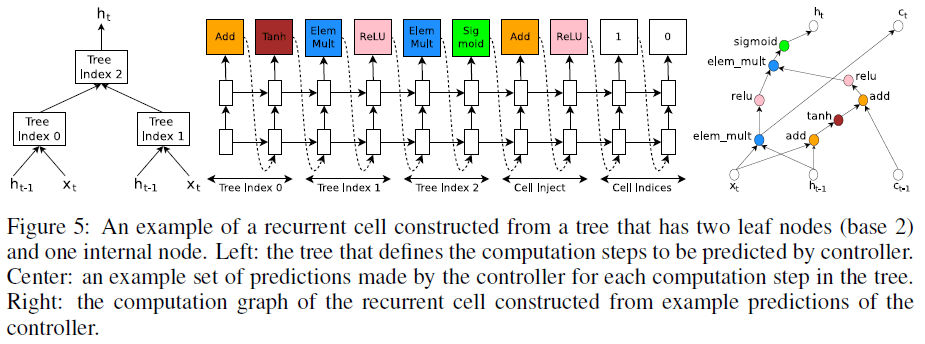
Figure 5 中图所示的网络生成步骤为:
- 在 Tree Index 0 阶段,控制器预测了 Add 和 Tanh,表示计算 $a_0 = \tanh(W_1 * x_1 + W_2 * h_{t-1})$。
- 在 Tree Index 1 阶段,控制器预测了 Elem Mult 和 ReLU,表示计算 $a_1 = \mathrm{ReLU}\big((W_3 * x_1) \odot (W_4 * h_{t-1})\big)$。
- 在 Cell Inject 阶段,控制器预测了 Add 和 ReLU;在 Cell indices 阶段,控制器预测的第 2 个元素为 $0$,表示将 $c_{t-1}$ 连接到 $a_0$,即计算 $a_0^{new} = \mathrm{ReLU}(a_0 + c_{t-1})$。
- 在 Tree Index 2 阶段,控制器预测了 Elem Mult 和 Sigmoid,表示计算 $a_2 = \mathrm{sigmoid}(a_0^{new} \odot a_1)$,注意 Figure 5 左图树节点最大索引为 2,则 $h_t = a_2$。
- 在 Cell indices 阶段,控制器预测的第 1 个元素为 $1$,表示 $c_t$ 为 Tree Index 1 在激活函数前的输出,即 $c_t = (W_3 * x_1) \odot (W_4 * h_{t-1})$。
由此就构建出了一个完成的 cell 结构。注意 Figure 5 左图的树有两个叶子节点,称为 base 2 架构。文章在实验中使用了 base 8 架构,以获取更强的表达能力。
3. 实验结果
文章在图像识别也语言建模两个任务上,验证了通过 NAS 所得到的网络的性能。
3.1. 生成 CNN
文章使用了 CIFAR-10 数据集来生成 CNN 网络并验证其性能。使用了两层 RNN(每层 35 个隐藏单元)作为控制器,搜索空间包括卷积层、ReLU、batch norm、和 skip
connection,分别尝试了固定步长为 $1$ 和预测步长( $[1, 2, 3]$)两种步长方式。对于生成的网络,从训练集中随机抽取 $5000$ 个样本作为验证集,剩下的 $45000$ 个样本作为训练集,训练 50 个 epoch 后记录验证集准确率,据此更新控制器参数。控制器在初始阶段只生成较浅的网络(6 层),随着训练的进行(每 1600 个子网络样本),不断增加网络深度(深度 $\times 2$)。
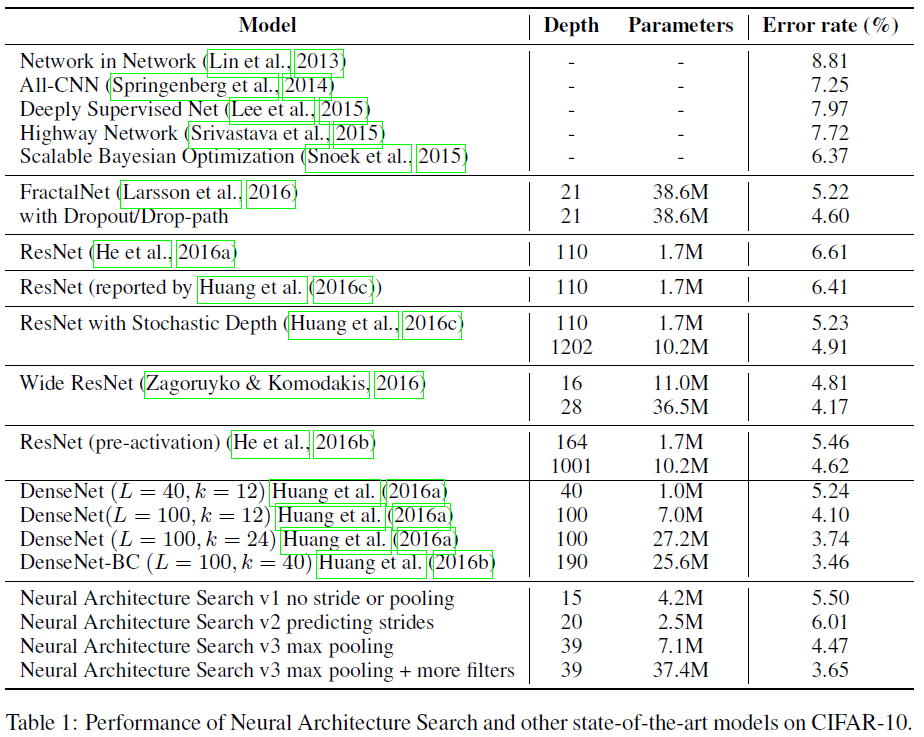
实验一共训练了 12800 个网络,从中选择最佳验证准确率的网络后,通过网格搜索学习率等超参数,然后进行测试,结果如 Table 1 所示。可见 NAS 生成的网络可以达到很好的性能,其中 39 层的模型到达了最佳的 3.65% 错误率,速度是 DenseNet (L = 100; k = 24) 的 1.05 倍。
3.2. 生成 recurrent cell
文章使用了 Penn Treebank 数据集来生成 recurrent cell 结构并验证其性能。使用了类似于 3.1 中的 RNN 控制器,搜索的操作包括 [add, elem_mult],搜索的激活函数包括 [identity, tanh, sigmoid, relu],base 为 8。生成 cell 结构后,用其构造一个两层的子网络并训练 35 个 epoch,并使用验证集的困惑度(perplexity)进行评价。
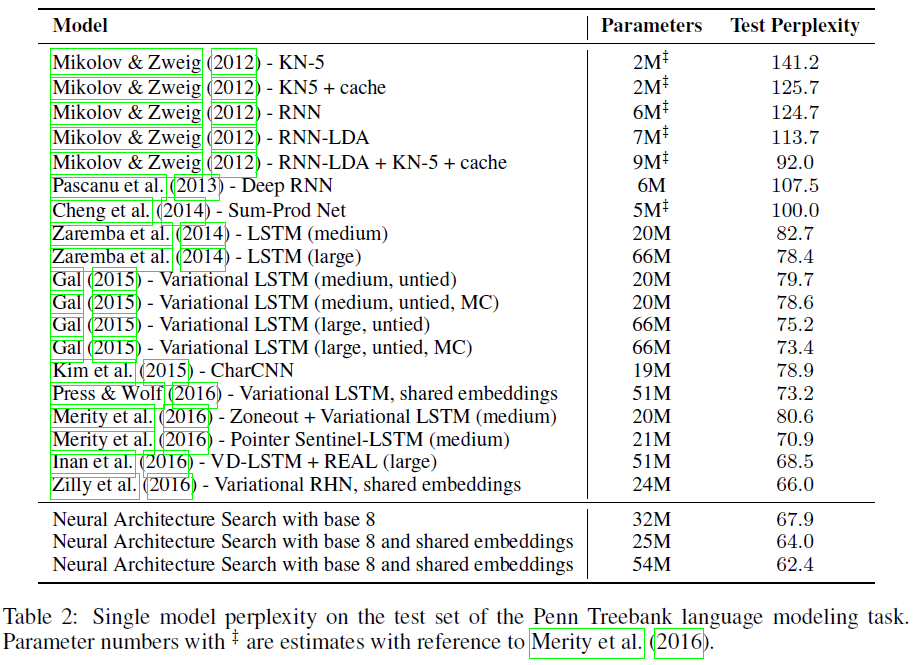
类似于生成 CNN 的流程,实验选择了最低验证集困惑度(perplexity)的结构,通过网格搜索学习率等超参数,实验结果如 Table 2 所示。可见 NAS 生成的 cell 结构也都获得了很好的性能,最佳模型达到了 62.4 的困惑度,较之前的最佳性能 66 降低了 3.6;其中困惑度为 64 的网络速度是之前最佳网络的 2 倍。
为了验证 NAS 生成的 cell 可以泛化到其他任务上,文章将其用于同一数据集的字符语言建模任务,结果如 Table 3 所示,可见新的 cell 结构可以泛化到其他任务,且性能优于 LSTM。