[Reading] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning (2016/2)
1. 概述
文章的主要贡献有:
- 在 Inception-v3 基础上,使用更统一的方式来设计不同尺寸的 block,以此构成 Inception-v4 的网络架构。
- 通过结合 Inception 模块和残差连接,提出了 Inception-ResNet-v1/v2 网络架构,大幅加快了 Inception 网络的训练速度。Inception-ResNet-v1 的计算量和性能与 Inception-v3 相似,Inception-ResNet-v2 的计算量和性能与 Inception-v4 相似,达到了当时的 SOTA 性能。
- 针对训练较深网络时残差不稳定的问题,在对残差进行相加前,先通过残差缩放来缩小残差,提高训练的稳定性。
2. Inception-v4 网络架构
文章提到,之前在设计 Inception-v3 时受到训练框架的限制,在实验中修改模型架构时比较保守,导致模型变得更复杂。在迁移到 TensorFlow 后,之前的限制不复存在,得以使用更统一的方式来设计不同尺寸的 block,以此构成 Inception-v4 的网络架构。
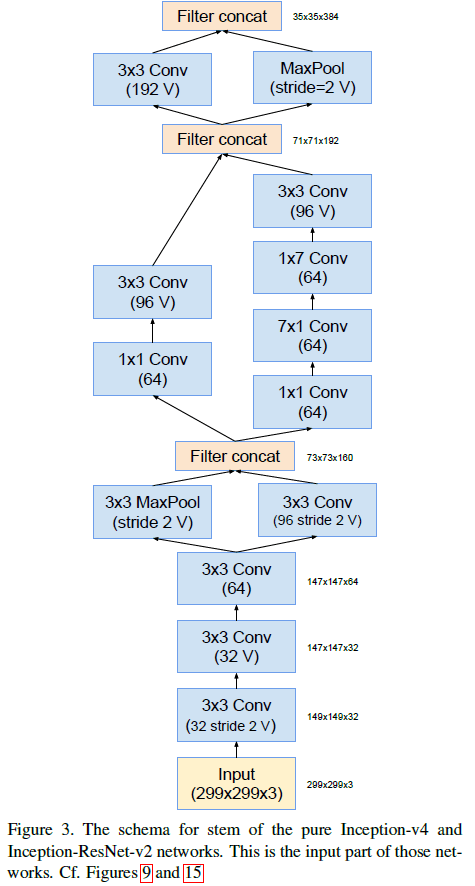
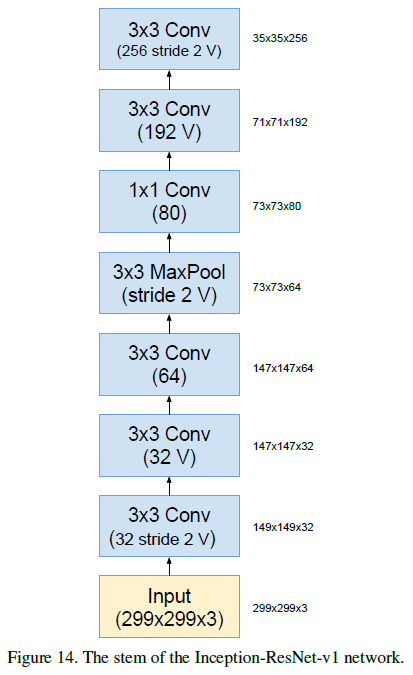
Inception-v4 和 Inception-ResNet-v2 的 stem 结构如 Figure 3 所示,这里 stem 指的是在 Inception 模块之前的结构。其中标有 V 的卷积表示使用了 valid padding,输出尺寸会缩小;没有标记 V 的卷积使用了 same padding,输出和输入尺寸相同。
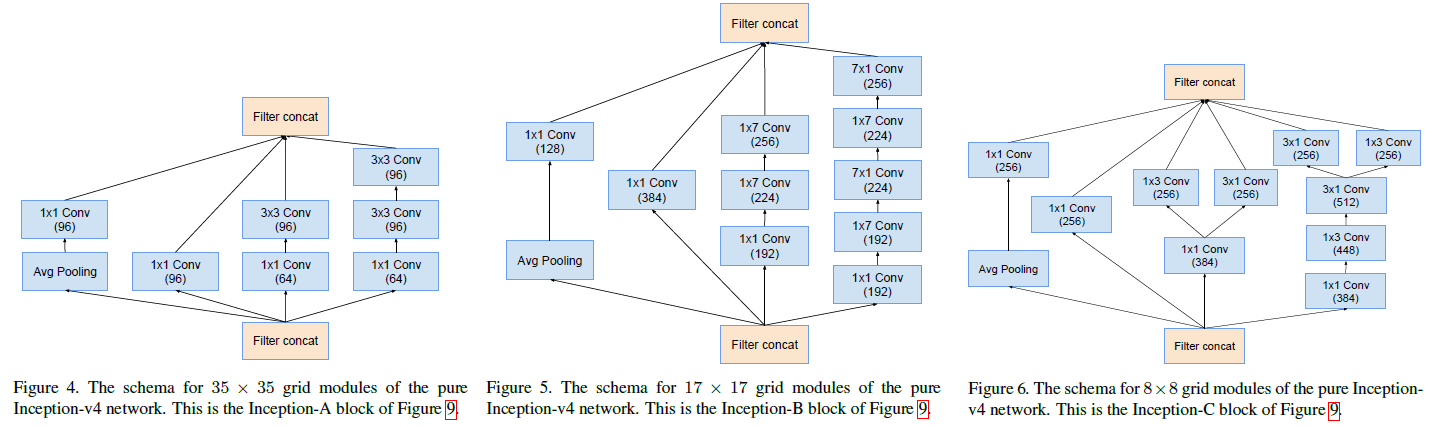
Inception-v4 中使用的 Inception-A、Inception-B、Inception-C 三种 block 如 Figure 4、5、6 所示。这些结构与 Inception v2/v3 中使用的对应结构非常相似。
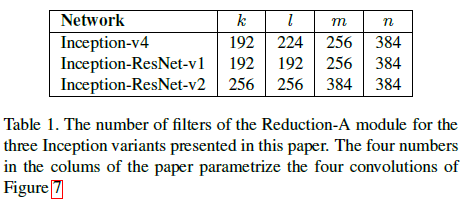
Inception-v4 中使用的两种 reduction 模块 Reduction-A 和 Reduction-B 如 Figure 7、8 所示,也采用了 Inception v2/v3 中并行卷积和池化的方法,来实现进行高效的尺寸缩减。Figure 7 中 $k, l, m, n$ 的取值如 Table 1 所示。

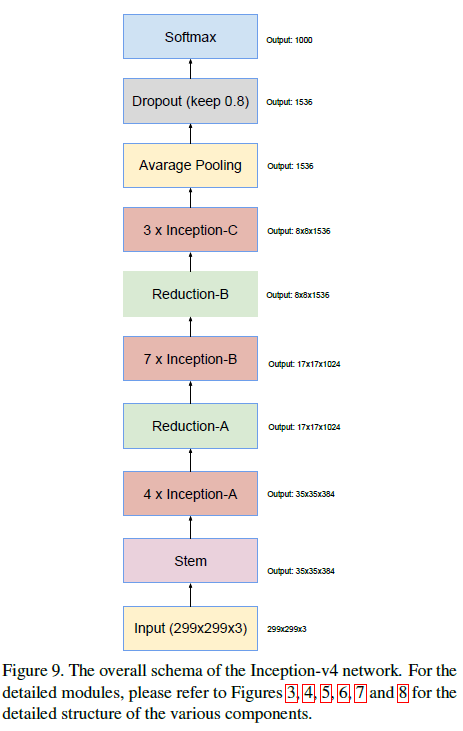
使用以上结构,Inception-v4 的整体结构如 Figure 9 所示。
3. Inception-ResNet 网络架构
在本文之前,Inception-v3 和 ResNet 都取得了非常不错的效果。ResNet 中的残差连接(Figure 1、2)有助于训练更深的网络,Inception 网络具有很高的计算效率。文章通过将 Inception 模块中的过滤器拼接部分替换为残差连接,融合了两种结构的优点。

文章给出了 Inception-ResNet-v1 和 Inception-ResNet-v2 两种网络架构,前者的计算量相当于 Inception-v3,后者的计算量相当于 Inception-v4。Inception-ResNet 中使用的 Inception block 更加简单,由于 Inception block 会压缩维度,每个 block 最后都会通过一个没有激活函数的 $1 \times 1$ 卷积,将输出的维度扩大到与输入相匹配,然后进行相加。由于受到内存限制,为了让模型能够在单个 GPU 上训练,Inception-ResNet 只在传统层上使用了 batch norm,而没有在 Inception block 在相加后使用 batch norm,由此可以大幅增加 Inception block 的数量。
Inception-ResNet-v1 的 stem 结构如 Figure 14 所示,Inception-ResNet-v2 的 stem 结构与 Inception-v4 相同,如 Figure 3 所示。
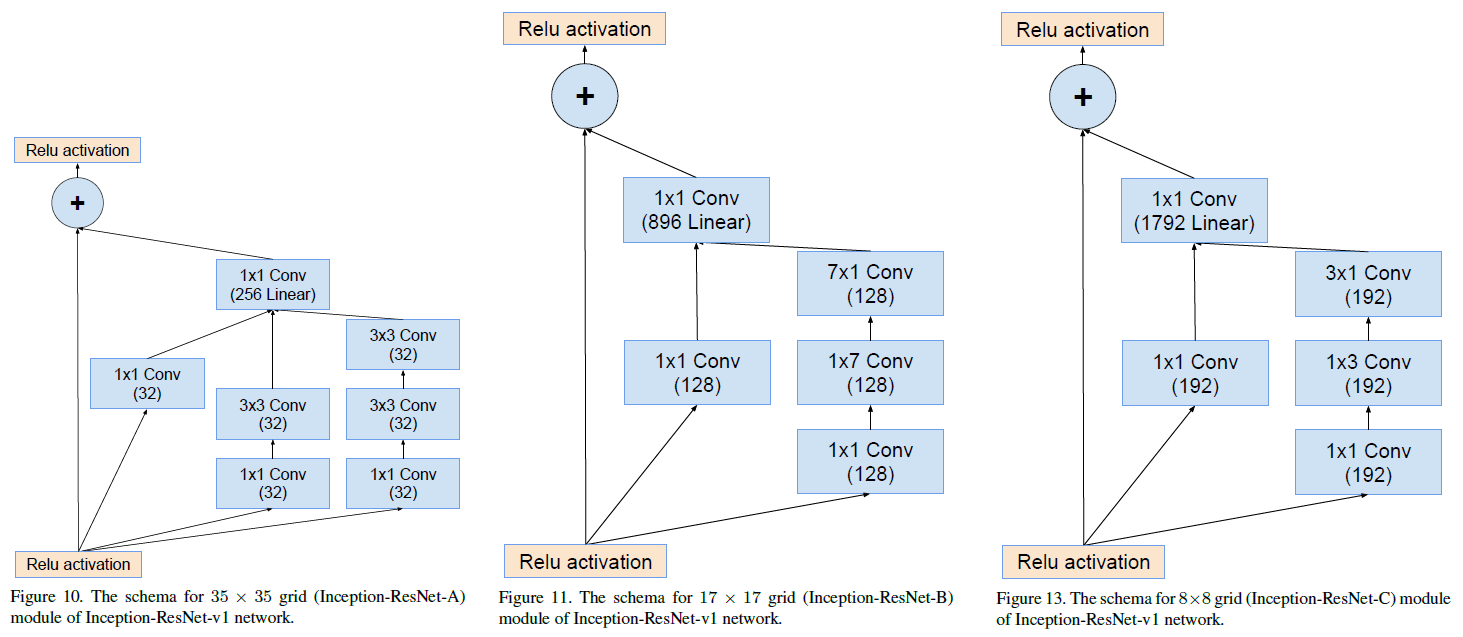
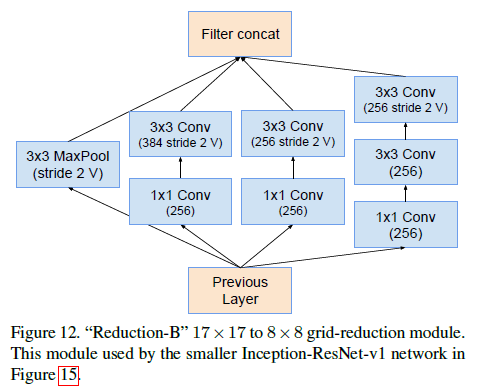
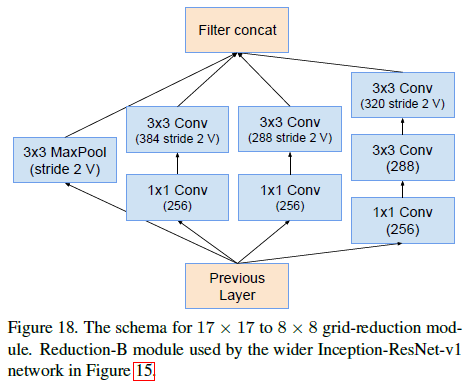
Inception-ResNet-v1 中使用的 Inception-ResNet-A、Inception-ResNet-B、Inception-ResNet-C 三种 block 如 Figure 10、11、13 所示,注意到在相加前都有一个 $1 \times 1$ 卷积。 使用的 Reduction-B 结构如 Figure 12 所示。
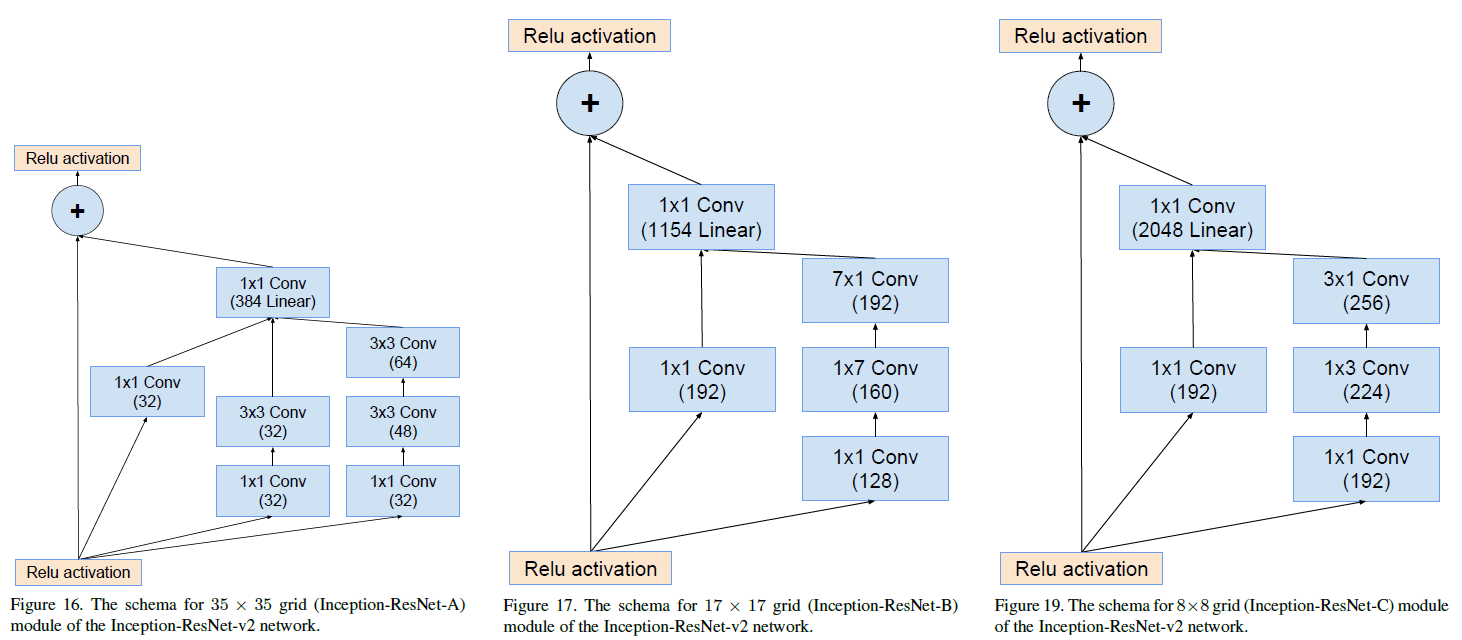
Inception-ResNet-v2 中使用的 Inception-ResNet-A、Inception-ResNet-B、Inception-ResNet-C 三种 block 如 Figure 16、17、19 所示。使用的 Reduction-B 结构如 Figure 18 所示。
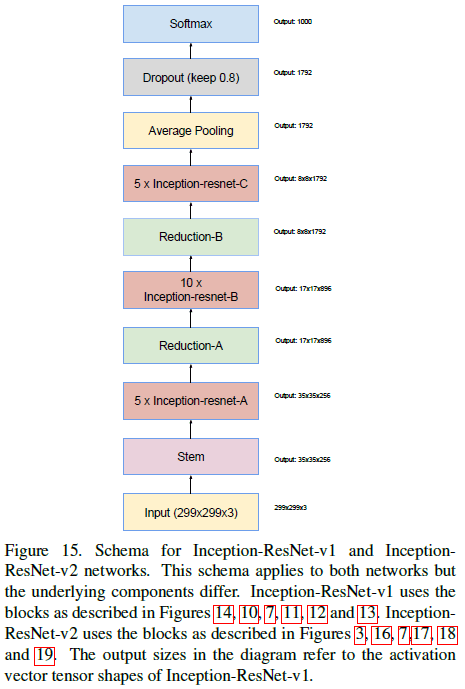
结合以上结构,Inception-ResNet-v1/v2 的整体结构如 Figure 15 所示。
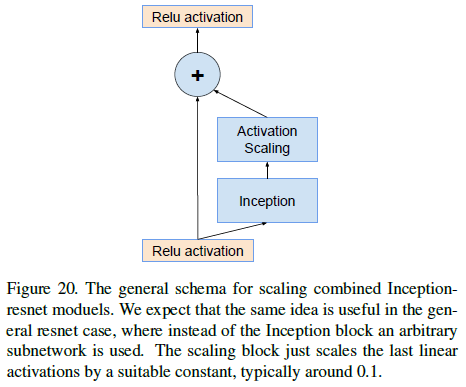
4. 残差缩放
文章发现,当过滤器数量超过 1000 时,残差会变得不稳定,平均池化前的输出在几万轮迭代后就会变成零,降低学习率或者使用额外的 batcn norm 都没有改善。文章发现在对残差进行相加前,先对残差进行缩小,如 Figure 20 所示,有助于训练的稳定。文章选择的缩小系数在 0.1 到 0.3 之间。
类似的问题在特别深的 ResNet 中也有出现,ResNet 的解决方法是分两步进行训练:先使用很低的学习率进行预热,再使用较高的学习率。文章发现如果过滤器数量非常多,即便使用极低的学习率也无法解决不稳定的问题,而且后续加大学习率时还会破坏已有的效果。文章认为缩小残差是更可靠的方法,这种方法不会降低最终的准确率,但会让训练更加稳定。
5. 实验结果
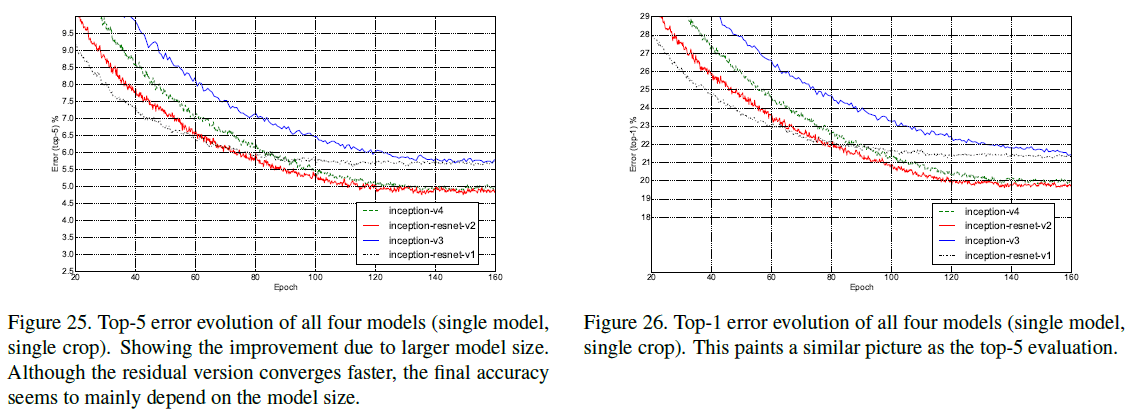
文章给出了 Inception-v3/v4 和 Inception-ResNet-v1/v2 在训练过程中的 top-5 和 top-1 错误率如 Figure 25、26 所示。可见 Inception-ResNet-v1 和 Inception-v3 性能相似,Inception-ResNet-v2 和 Inception-v4 性能相似,但使用了残差连接的网络训练速度要快于不使用的网络。
文章还给出了 single/multi crop、模型融合下各种模型的对比,Inception-v4 和 Inception-ResNet-v2 都达到了当时的 SOTA 水平。