Deep Learning Note: 4-5 卷积神经网络案例分析(1)
1. 经典网络
1.1. LeNet-5
LeNet-5 是一个用于识别手写数字的网络,由 Yann LeCun 等人于 1998 年提出。其结构如图 1 所示。
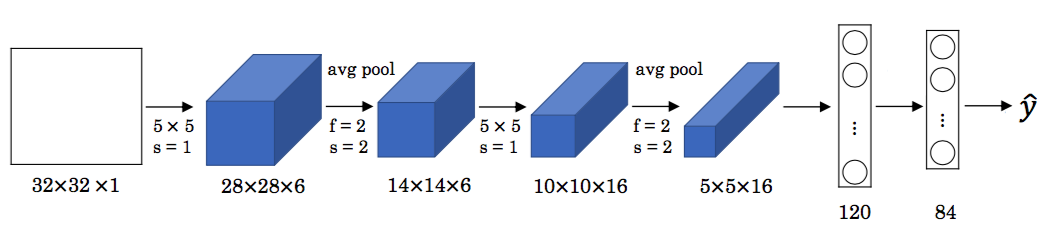
图 1
LeNet-5 的输入是一张 $32 \times 32$ 的灰度图像,只有一个通道。先是两组卷积层和池化层的组合,然后是两个全连接层,输出 $84 \times 1$ 的向量,再通过一个特定的分类器得到预测值 $\hat{y}$。注意 LeNet-5 中的池化都是平均池化,在 LeNet-5 提出的时期,平均池化使用得比较多,而现在通常会使用最大池化。另外现在通常会使用 Softmax 来得到 10 路输出作为预测。
在 LeNet-5 中,随着网络的深入,数据的高度($n_H$)和宽度$n_W$)逐渐缩小,通道数($n_c$))逐渐增加。此外 LeNet-5 还使用了若干个卷积层加池化层的组合、最后连接几个全连接层的结构。这些特征在现代的神经网络中也很常见。
以现在的标准来看,LeNet-5 是一个很小的网络,只有约 6 万个参数,现代的神经网络经常有上千万甚至上亿个参数。
由于 LeNet-5 的提出时间很早,原论文中的一些内容与现代常用的方式有一些区别。首先,可以看到当时人们使用 Sigmoid 和 Tanh 函数来获得非线性,没有使用现在常用 ReLU。其次,前文提到,过滤器的通道数要与输入数据的通道数一致,每个过滤器都会对输入的所有通道进行检测,即对于 $n_H \times n_W \times n_c$ 的输入,每个过滤器的大小为 $f \times f \times n_c$。而在 LeNet-5 提出的时候,受限于计算能力,通过非常复杂的方法,使用不同的过滤器检测不同的通道,以此降低计算量,现在则不会考虑这些问题。最后,LeNet-5 在池化层后引入了非线性,而现在则会在卷积层后通过激活函数获得非线性,在池化层后不再引入非线性。
1.2. AlexNet
AlexNet 由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey E. Hinton 于 2012 年提出,赢得了 2012 年的 ImageNet ILSVRC挑战赛,且性能远超第二名。AlexNet 的结构如图 2 所示。
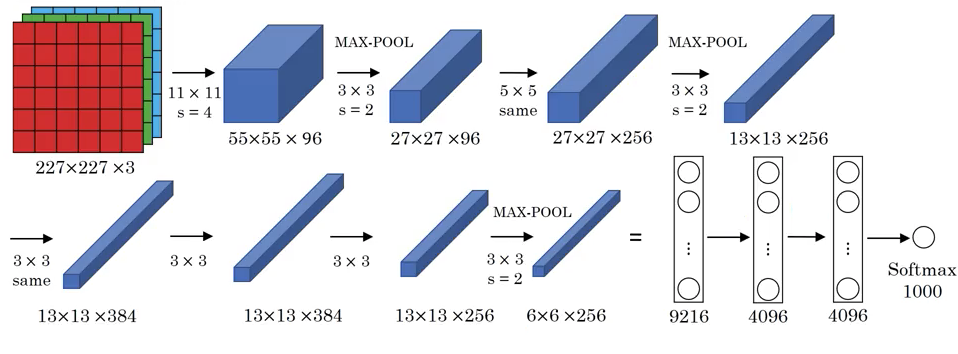
图 2
图 2 中的 “same” 表示使用了 Same Padding。AlexNet 与 LeNet 虽然有很多类似之处,但 AlexNet 的规模远大于 LeNet,约有 6 千万个参数,而且AlexNet 使用 ReLU 作为激活函数。在 AlexNet 提出的时候,GPU 的速度还没有现在这么快,当时使用了两个 GPU 来进行训练。AlexNet 中还使用了 Local Response Normalization(LRN)层,即对所有通道中同一个位置上的像素之间进行标准化,避免出现很多特别高的激活值。
在 AlexNet 之前,深度网络就已经在语音识别等领域有了一些应用,但 AlexNet 用事实展现了深度学习的能力,其论文在计算机视觉以及其他领域都产生了很大的影响。
1.3. VGG-16
VGG-16 是由 Karen Simonyan 和 Andrew Zisserman 于 2014 年提出的,其中只使用了以下两种基本结构:
- CONV:卷积层,$3 \times 3$,$s = 1$,Same Padding
- POOL:最大池化层,$2 \times 2$,$s = 2$
VGG-16 的结构如图 3 所示。
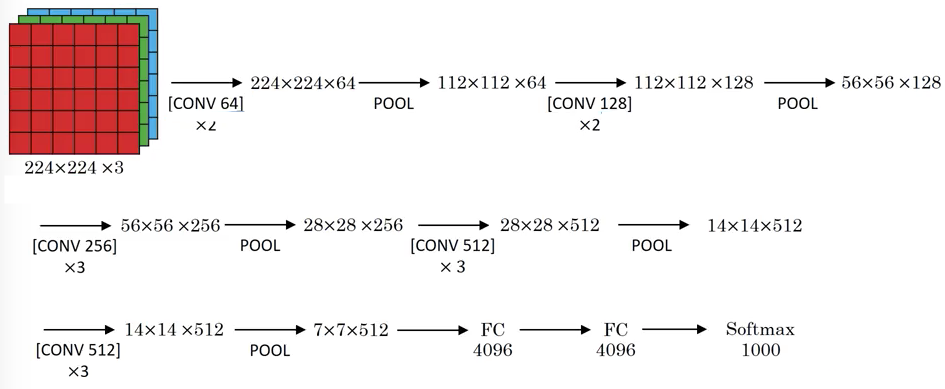
图 3
VGG-16 是一个非常大的网络,约有 1.38 亿个参数,但它的结构非常规律,每一层都由一个卷积层和池化层组成。注意卷积层中过滤器的数量逐层翻倍(直到 512),这也是在神经网络结构设计中的一种常用技巧。VGG-16 中每一层卷积层都会让数据的通道数增加一倍,然后通过池化层让数据的高度和宽度减半。
VGG-16 中的 16 表示网络中有 16 个带有权重的层,它有一个变种称为 VGG-19,VGG-19 是一个更大的网络。